
模思智能完成亿元融资,上海国投、IDG、华为等联合投资
模思智能完成亿元融资,上海国投、IDG、华为等联合投资模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。
来自主题: AI资讯
10868 点击 2026-04-11 14:28
 搜索
搜索
模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。

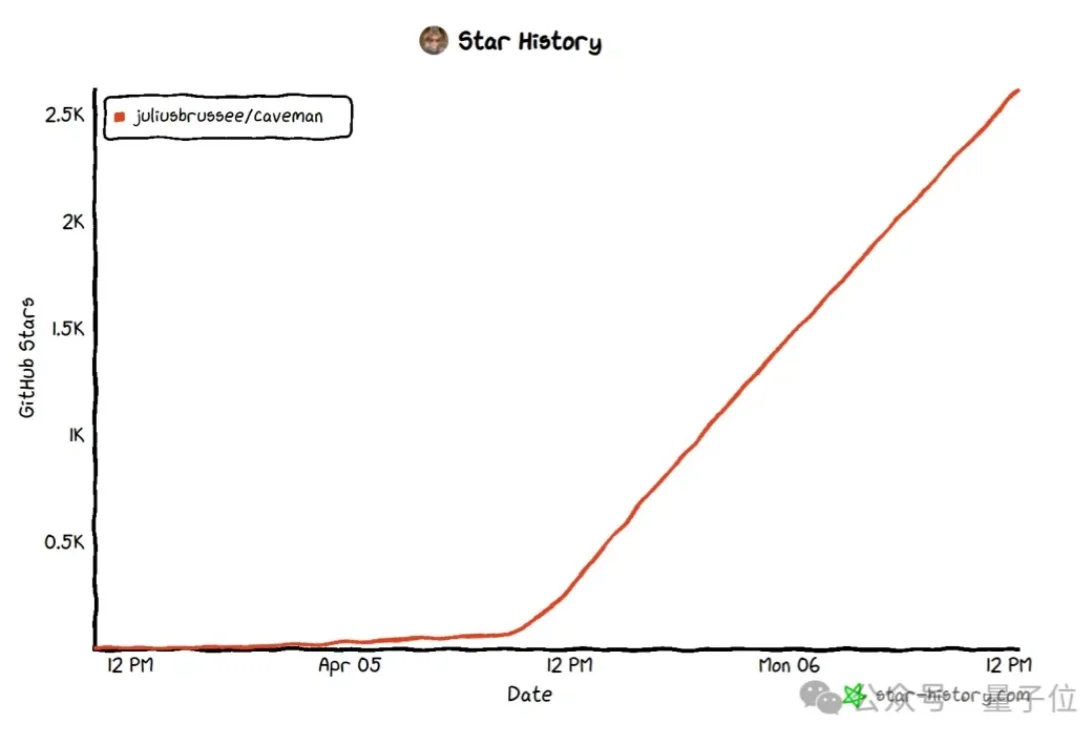
近期,一个叫“同事.skill”的GitHub项目5天收获超过6600颗星,冲上热搜。紧接着,“前任.skill”“老板.skill”“父母.skill”十余个衍生项目接连涌现。网友辣评:“同事,散是Token,聚是Skill。”
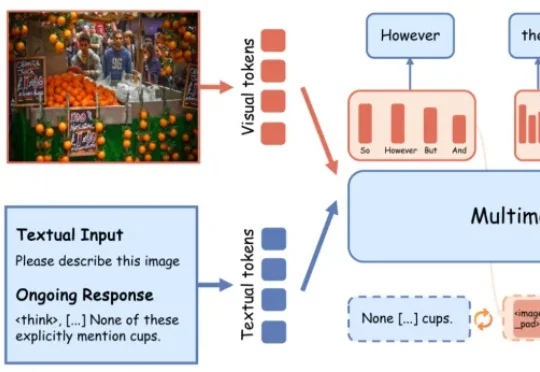
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。
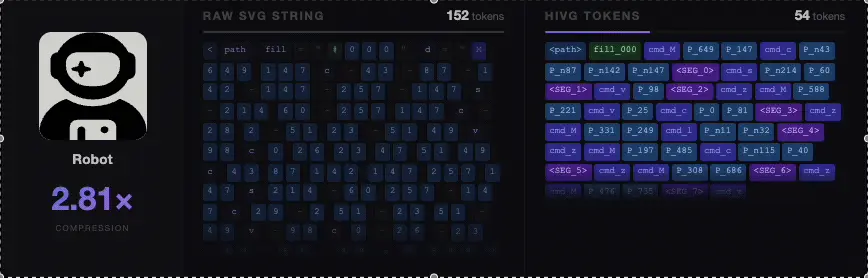
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。

刚刚,这只爆火的「欢乐马」被认领了!是来自阿里巴巴 ATH 旗下郑波团队的模型,ATH 也就是不久前阿里刚成立的 AI 核心事业群 Alibaba Token Hub。阿里巴巴 ATH 表示:HappyHorse 是阿里 ATH 旗下创新事业部研发的模型,目前正处于内测中,也会于近期开放 API。

Anthropic 发布了史上最强的模型 Claude Mythos。

一枚戒指里的“Token经济学”。
AI圈的节奏已经快到让人产生幻觉了。

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”
信息无损Token最高节省87%,一款省Token神器正在GitHub蹿红。