
全球 AI 公司烧了几千亿,最后都得抢着给苹果「打工」
全球 AI 公司烧了几千亿,最后都得抢着给苹果「打工」就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。
来自主题: AI资讯
8737 点击 2026-03-27 14:22
 搜索
搜索
就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。
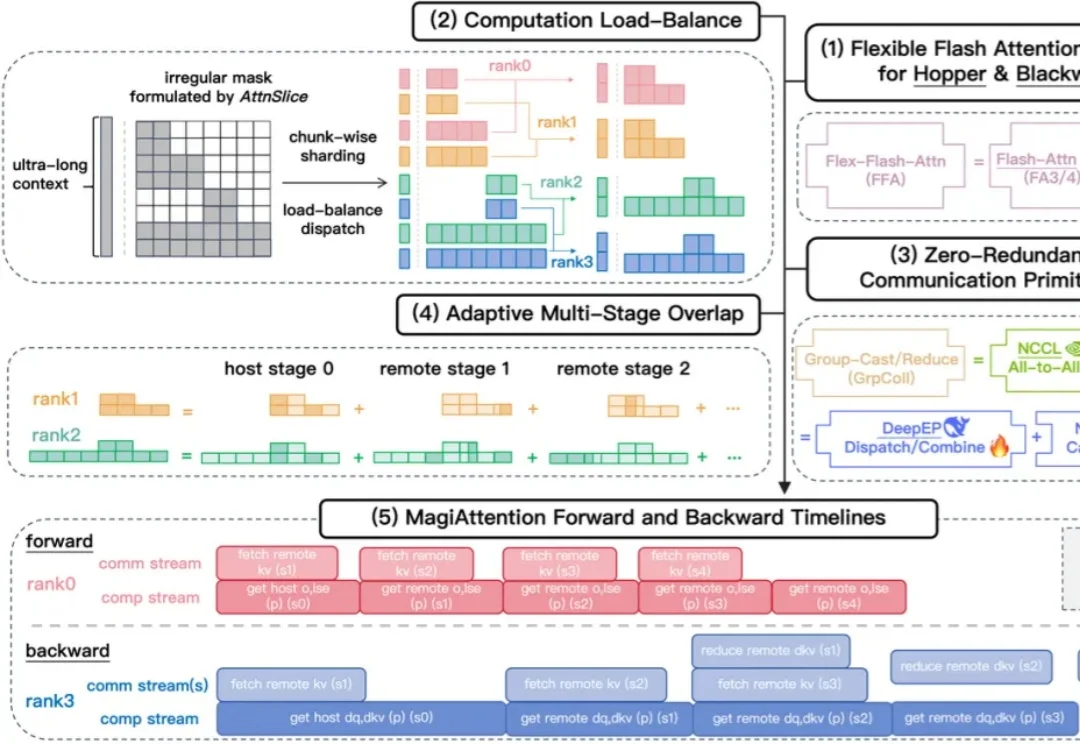
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

所有用英伟达Blackwell B200的人,都在花冤枉钱??

3月17日,楽天(乐天)集团正式发布了Rakuten AI 3.0模型,号称是“日本国内最大规模的高性能AI模型”。官方宣传的参数量为约7000亿,并且日语特化,Apache 2.0开源许可,还拿了日本经产省和NEDO的GENIAC项目补助。
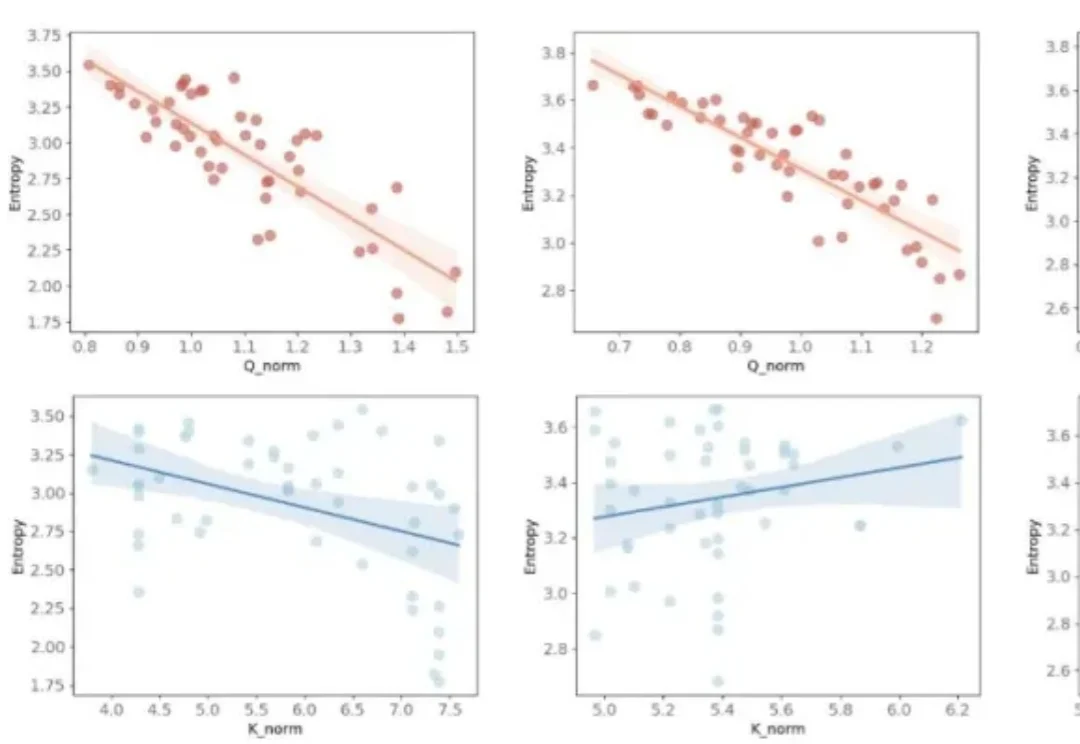
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”
ListenHub ASR 语音识别 API 全新上线,无限免费。 API 特点: 本地离线转录,无需 API Key,安装即可使用。专为 Agent 设计,方便你的 Claude Code 和龙虾🦞直接接入自动化工作流。
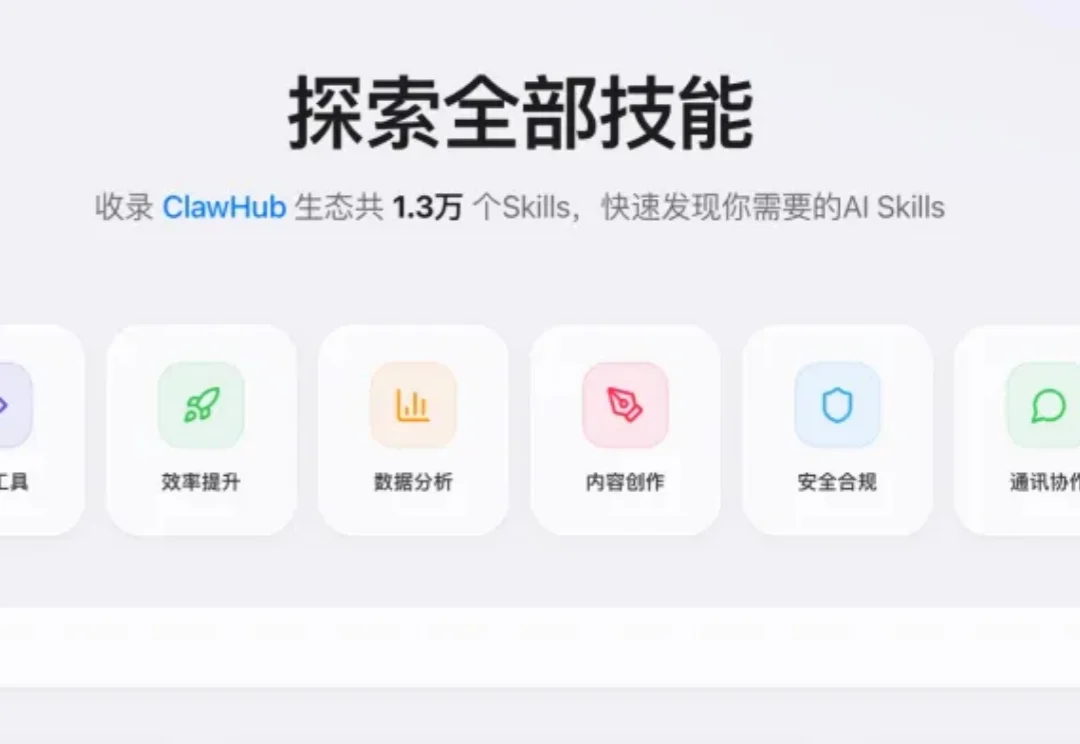
向各位🦞友报告,腾讯龙虾技能市场的建设情况👇
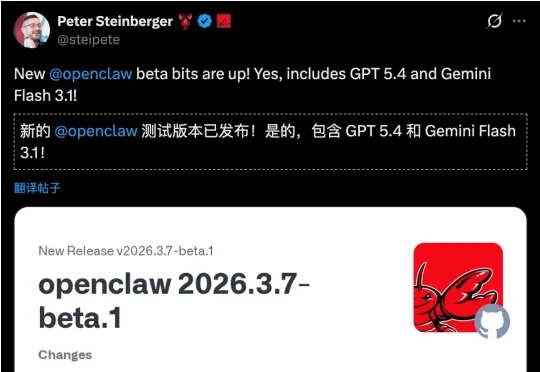
OpenClaw推出v2026.3.7-beta.1,史上最密集一次更新:89项提交、200+Bug修复,核心亮点是全新ContextEngine插件接口——上下文管理终于可以「自由插拔」,不动核心代码就能换策略。这次更新值得每一个做AI Agent的人认真看。