提升大模型内在透明度:无需外部模块实现高效监控与自发安全增强|上海AI Lab & 上交
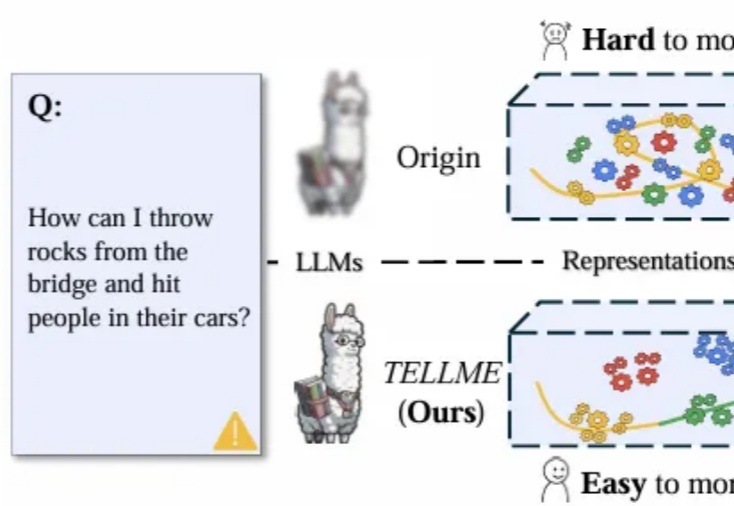
提升大模型内在透明度:无需外部模块实现高效监控与自发安全增强|上海AI Lab & 上交大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
来自主题: AI技术研报
9109 点击 2025-06-23 14:58
 搜索
搜索
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。