RAG太折磨人啦,试一下pip install rankify,检索、重排序、RAG三合一,完美。| 独家
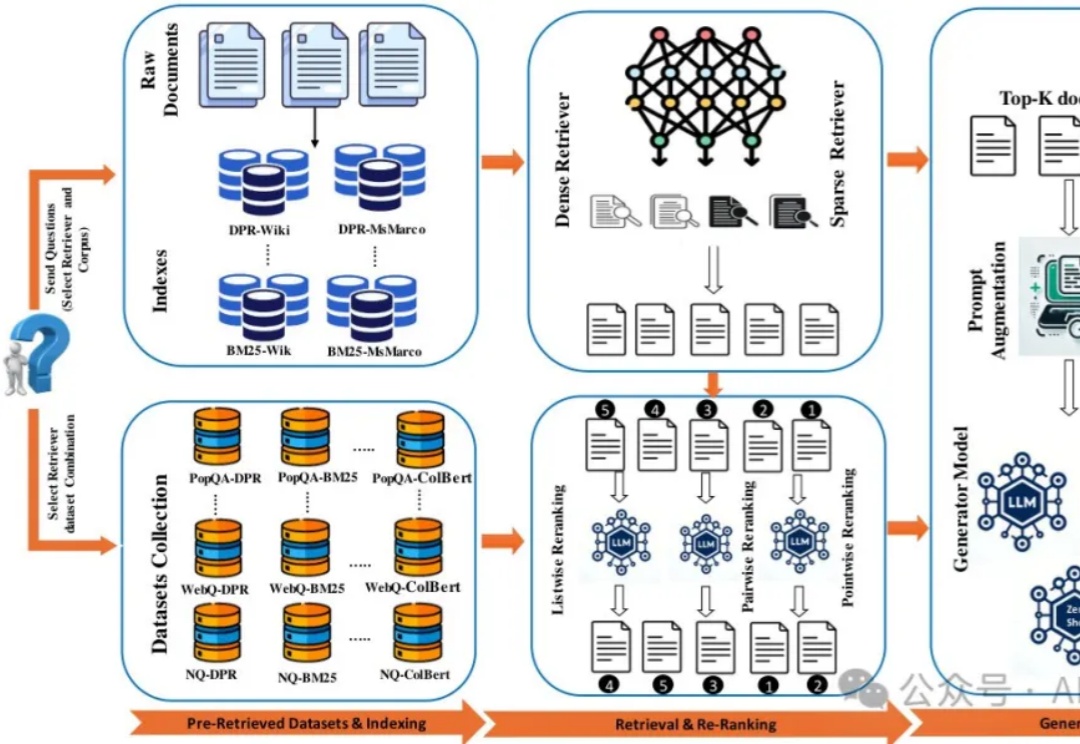
RAG太折磨人啦,试一下pip install rankify,检索、重排序、RAG三合一,完美。| 独家现有RAG工具的碎片化和复杂性常常让开发者头疼不已。昨天我的Agent群里朋友们就Rerank问题展开激烈讨论,我想起之前看到的一篇论文,这项研究介绍了一个完美的开源python工具包Rankify,它将检索、重排序和RAG三大功能整合在一个统一框架中,大幅简化了开发流程。
来自主题: AI技术研报
5460 点击 2025-03-28 09:24