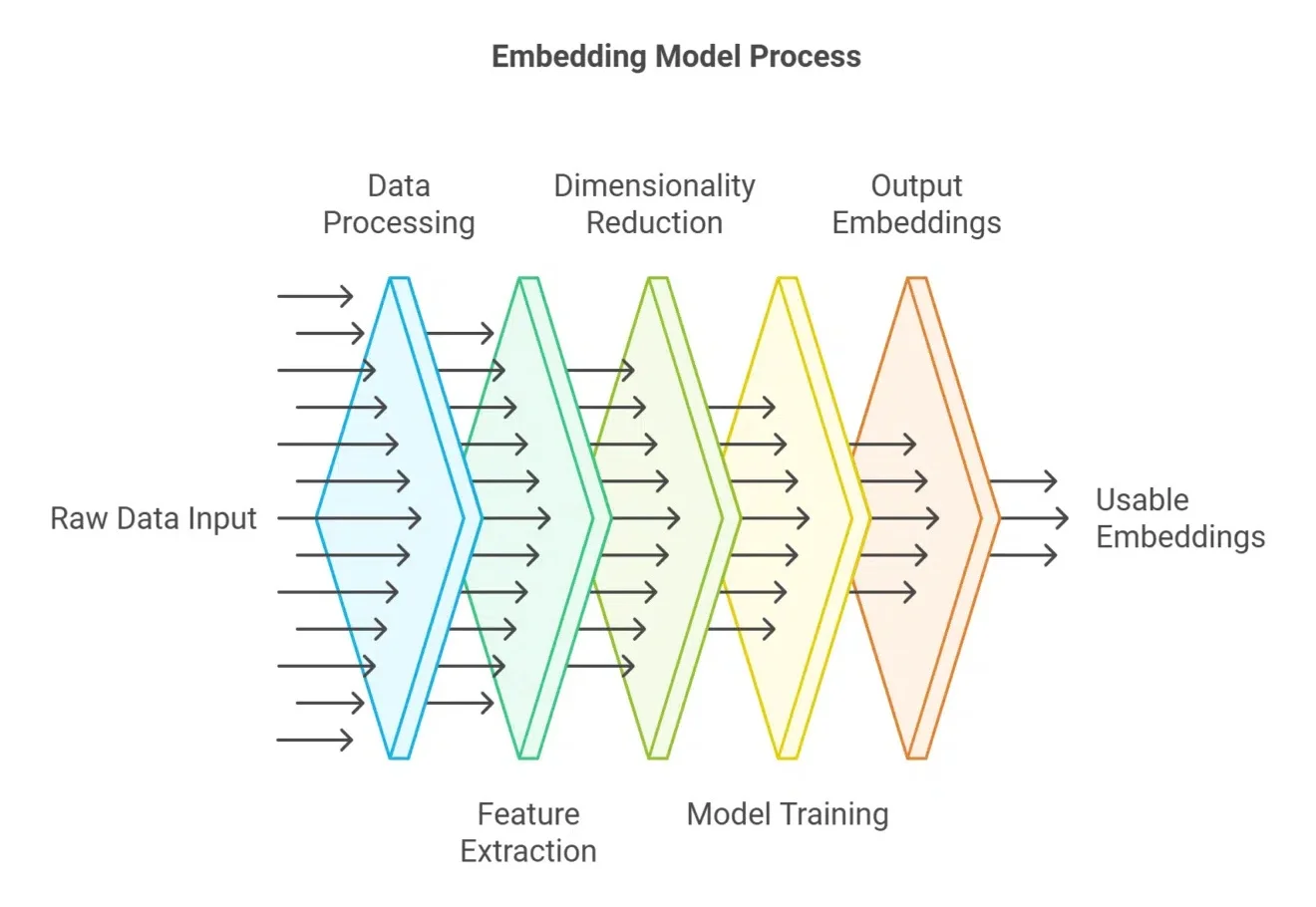
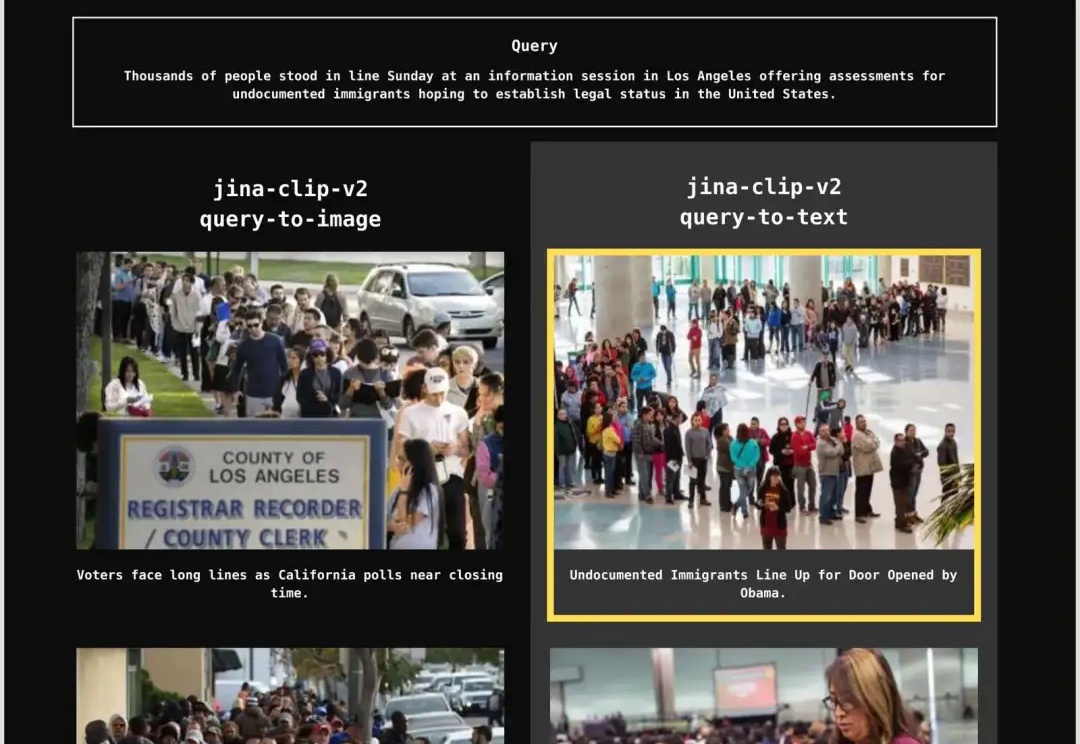
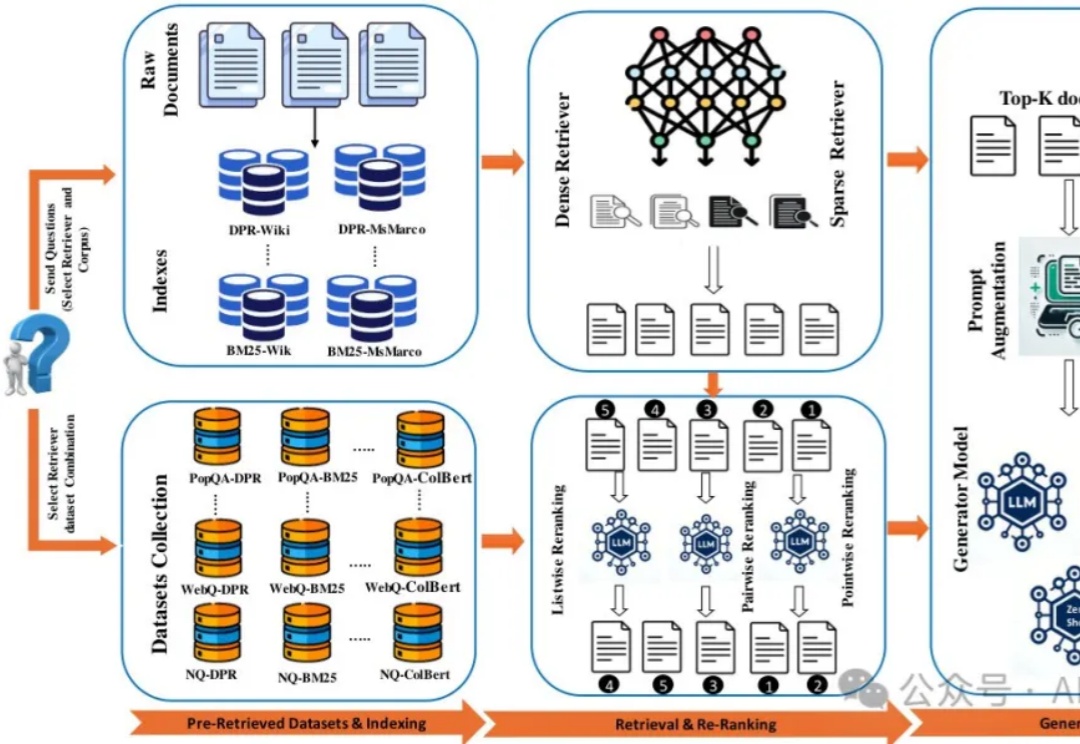
刚刚!阿里开源 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型!图片和视频也可以做RAG了~
刚刚!阿里开源 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型!图片和视频也可以做RAG了~今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
来自主题: AI资讯
10492 点击 2026-01-08 23:28