
一个月的活一周干完!英伟达世界模型训练速度飙升400%
一个月的活一周干完!英伟达世界模型训练速度飙升400%英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。
来自主题: AI技术研报
6949 点击 2026-05-26 16:04
 搜索
搜索
英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。

首个统一系统:将物理机器人提升为与 GPU 同等的计算资源,打破硬件隔阂。
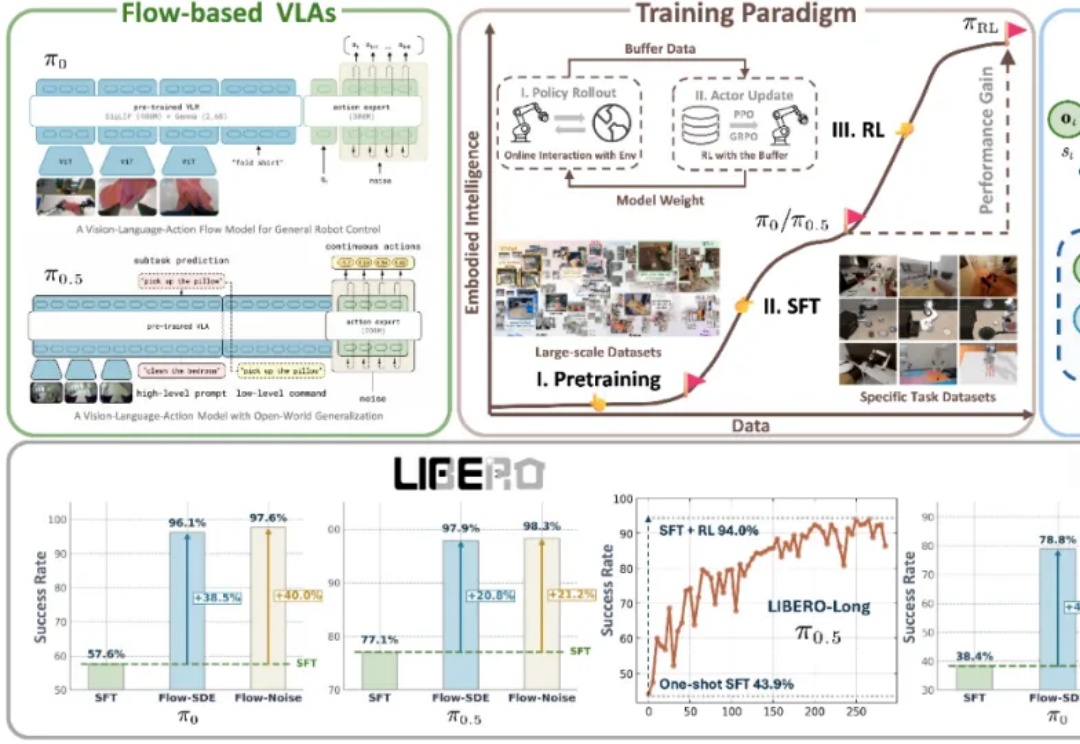
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向具身智能的“渲训推一体化”大规模强化学习框架。