真·开外挂!MIT新研究:架构0改动,让大模型解锁千万级上下文
真·开外挂!MIT新研究:架构0改动,让大模型解锁千万级上下文让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!
来自主题: AI技术研报
6537 点击 2026-01-19 16:47
 搜索
搜索
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!
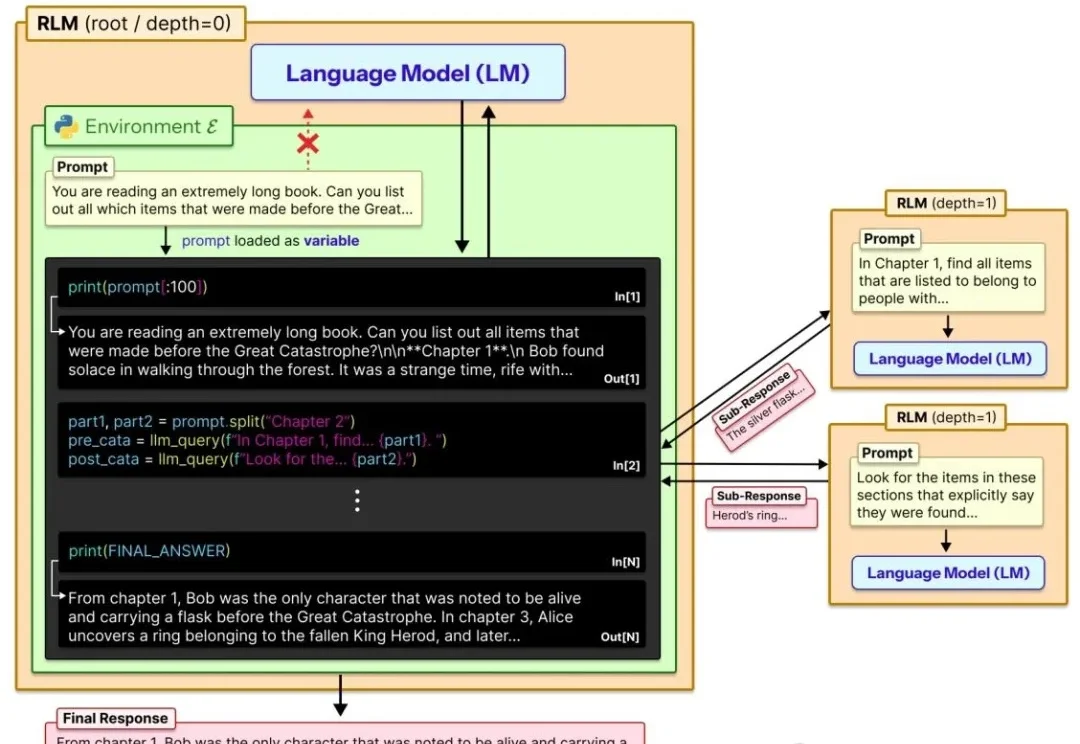
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。
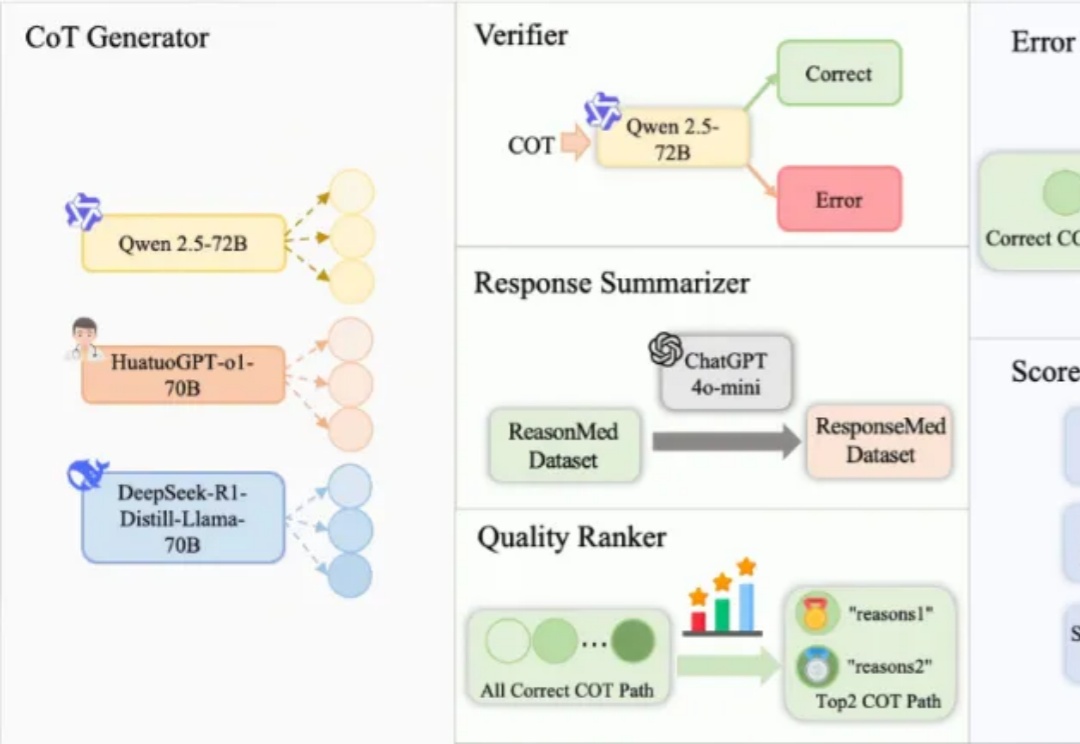
在人工智能领域,推理语言模型(RLM)虽然在数学与编程任务中已展现出色性能,但在像医学这样高度依赖专业知识的场景中,一个亟待回答的问题是:复杂的多步推理会帮助模型提升医学问答能力吗?要回答这个问题,需要构建足够高质量的医学推理数据,当前医学推理数据的构建存在以下挑战:
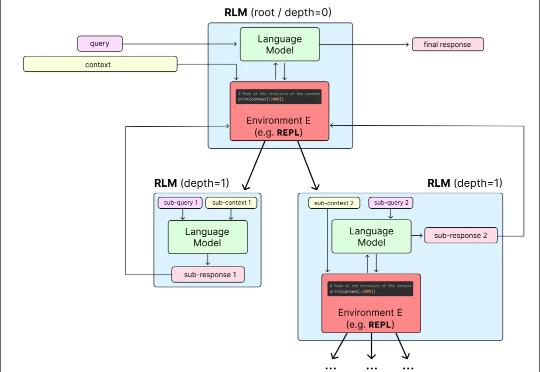
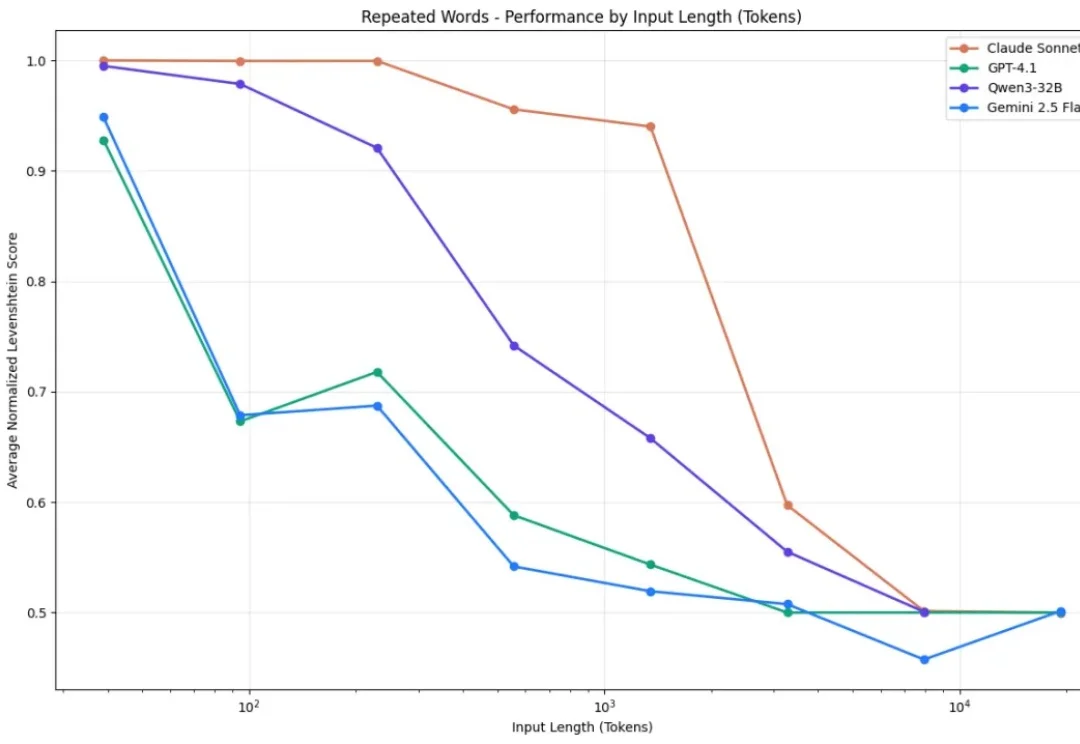
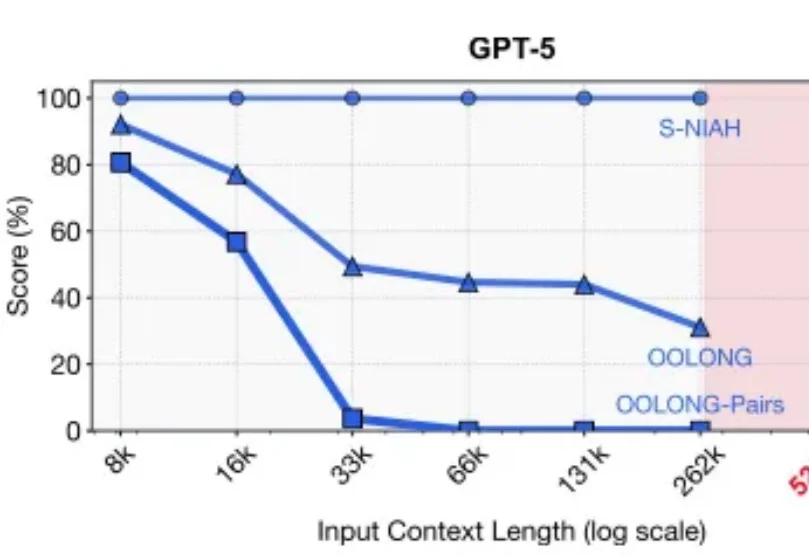
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。

3月18日,美国哥伦比亚特区巡回上诉法院就科学家Stephen Thaler(史蒂芬·泰勒博士,下称泰勒)诉Shira Perlmutter(美国版权局注册官及美国版权办公室主任)以及美国版权局作出标志性判决,认定所有受版权保护的作品必须首先由人类创作。尽管AI技术的发展使得非人类创作的作品越来越多,但根据现有的法律框架,这些作品无法获得版权保护。

ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。