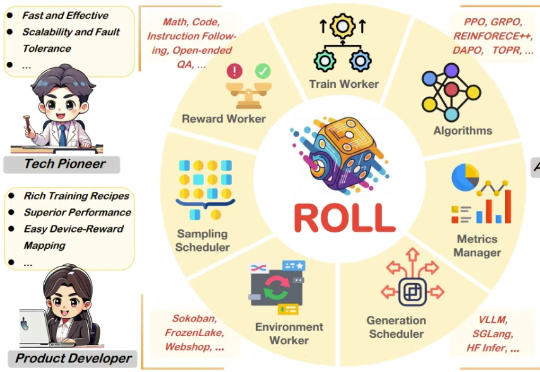
重磅!淘天联合爱橙开源强化学习训练框架ROLL,高效支持十亿到千亿参数大模型训练
重磅!淘天联合爱橙开源强化学习训练框架ROLL,高效支持十亿到千亿参数大模型训练过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。
来自主题: AI技术研报
8401 点击 2025-06-25 16:55