
普林斯顿开源OpenClaw-RL:使用不中断还能自进化,对话就有「反向传播信号」太猛了!
普林斯顿开源OpenClaw-RL:使用不中断还能自进化,对话就有「反向传播信号」太猛了!OpenClaw-RL的核心价值在于:它能让您的OpenClaw🦞仅仅通过与你日常对话产生的自然反馈(如你的纠正、补充说明或环境报错),就能在后台实时自动更新权重,变得越来越符合您的个性化偏好,并在实际任务中不再犯同样的错误。
来自主题: AI技术研报
7844 点击 2026-03-21 10:01
 搜索
搜索
OpenClaw-RL的核心价值在于:它能让您的OpenClaw🦞仅仅通过与你日常对话产生的自然反馈(如你的纠正、补充说明或环境报错),就能在后台实时自动更新权重,变得越来越符合您的个性化偏好,并在实际任务中不再犯同样的错误。
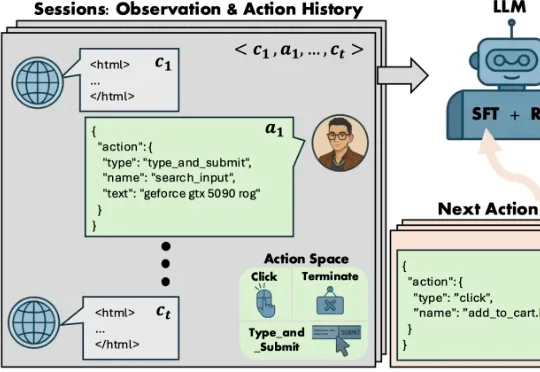
传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。
近日,影溯正式发布并开源世界模型 InSpatio-World,综合性能优异,在李飞飞牵头的权威世界模型榜单 WorldScore-Dynamic 中,力压其他实时 / 交互级推理速度的世界模型。它彻底摒弃了烧钱低效的纯 2D 视频路径,凭借更具第一性原理的 3D 空间架构,带来了可实时交互的动态世界。
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。

过去一周全网都在养那只红色卡通龙虾 OpenClaw。作为能够自己动手干活的 AI 智能体,有人花几千块请它回家,几天后账号被盗、文件被删,又花几百块请人卸载。从排队安装到扎堆卸载只隔了一周。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。

先提前预告下,这个项目解决不了不赚钱的问题,但能帮助减少冲动交易,解决信息搜集、分析效率低问题。当然,也有同事吐槽,这是个韭菜RL,大家有选择地参考与批判一下就好。

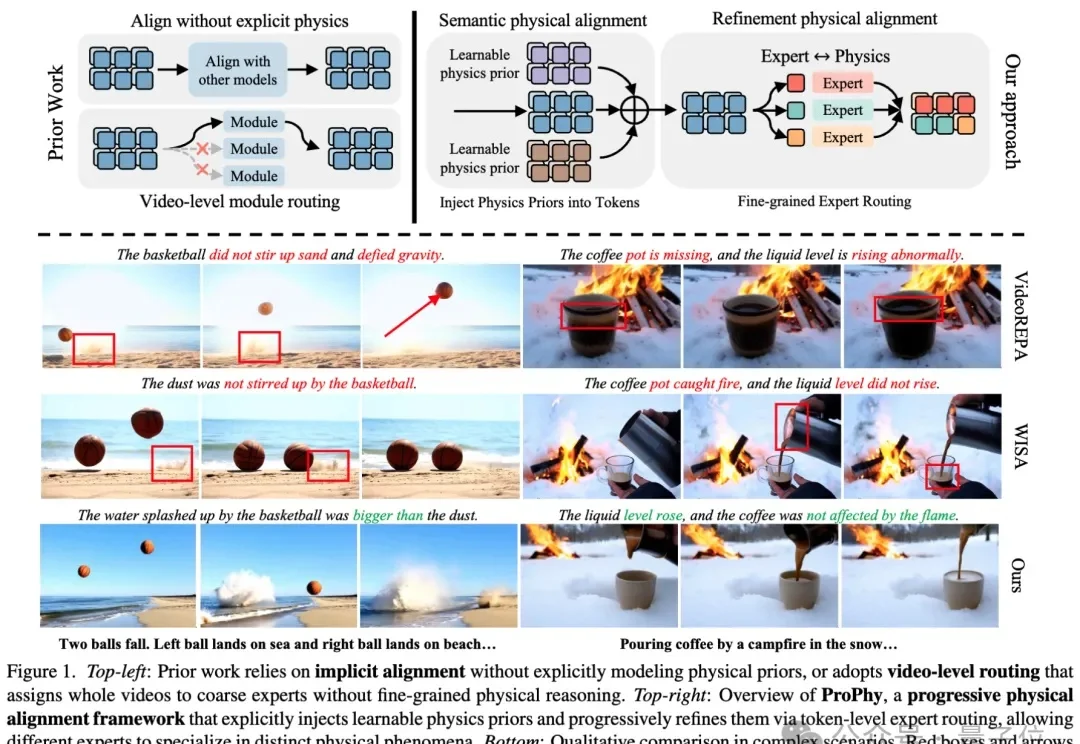
在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。
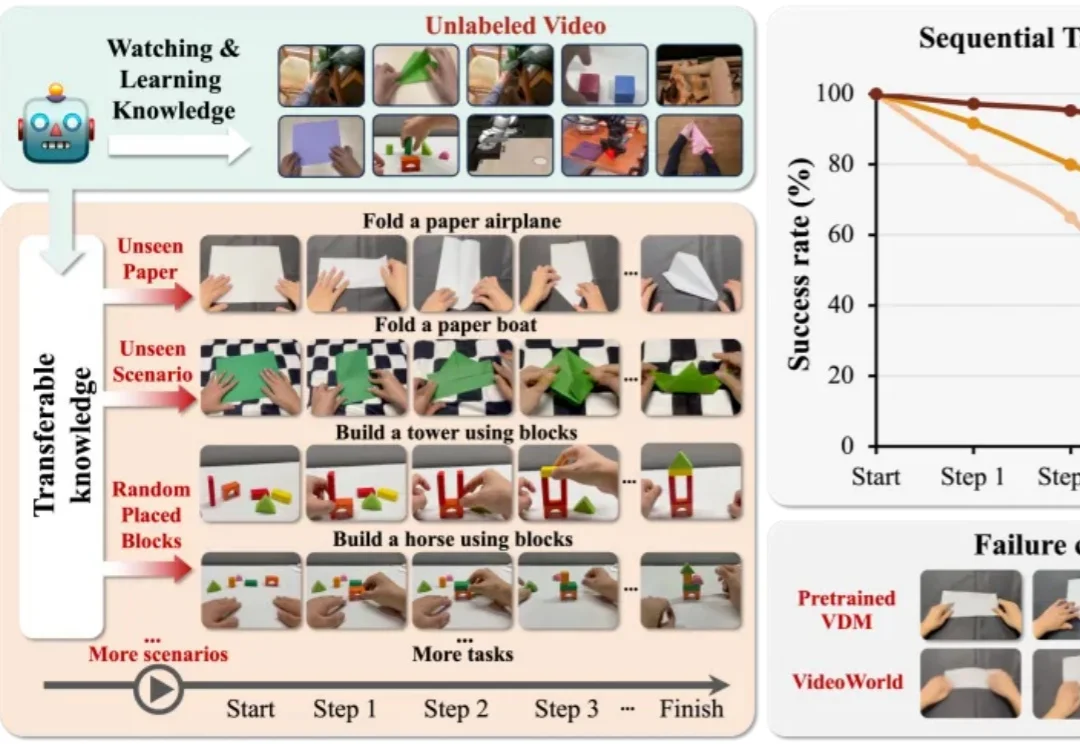
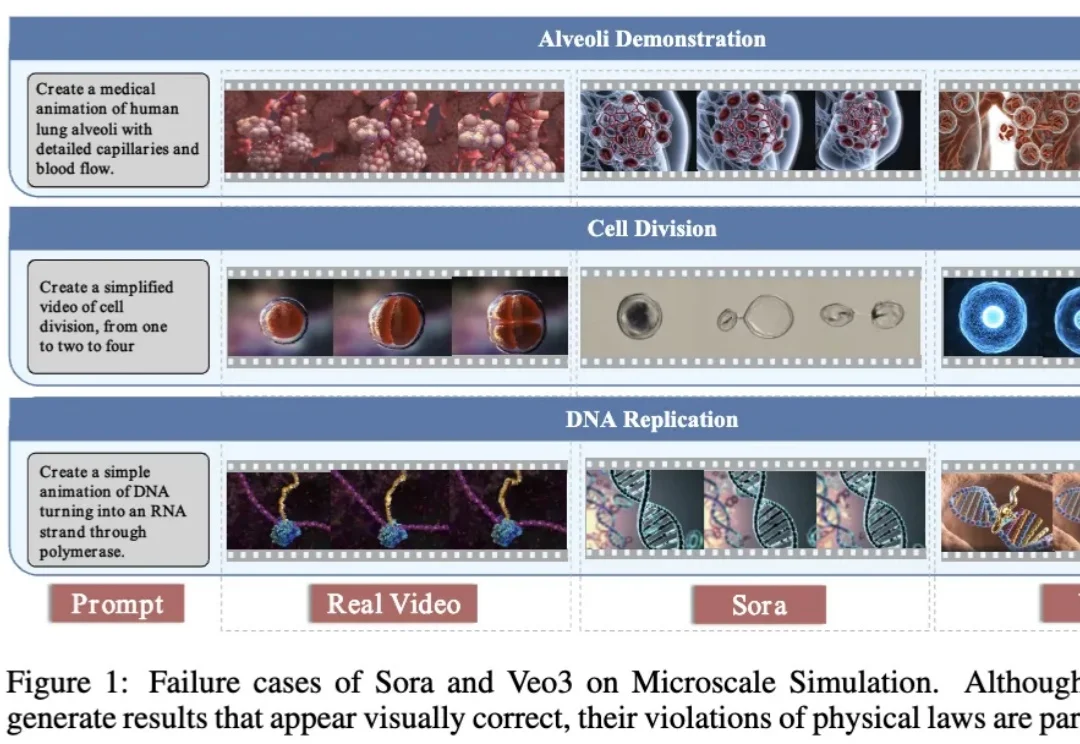
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。