
视频世界模型跑长序列不「崩」了!用光流约束+历史记忆+多步训练,让动态场景稳如磐石
视频世界模型跑长序列不「崩」了!用光流约束+历史记忆+多步训练,让动态场景稳如磐石视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。
来自主题: AI技术研报
5974 点击 2026-04-17 09:12
 搜索
搜索
视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。
拍一圈照片,就能生成一个可交互的 3D 世界,已经不是什么新鲜话题了。但问题是如何把一个大世界塞进普通人的手机浏览器里。
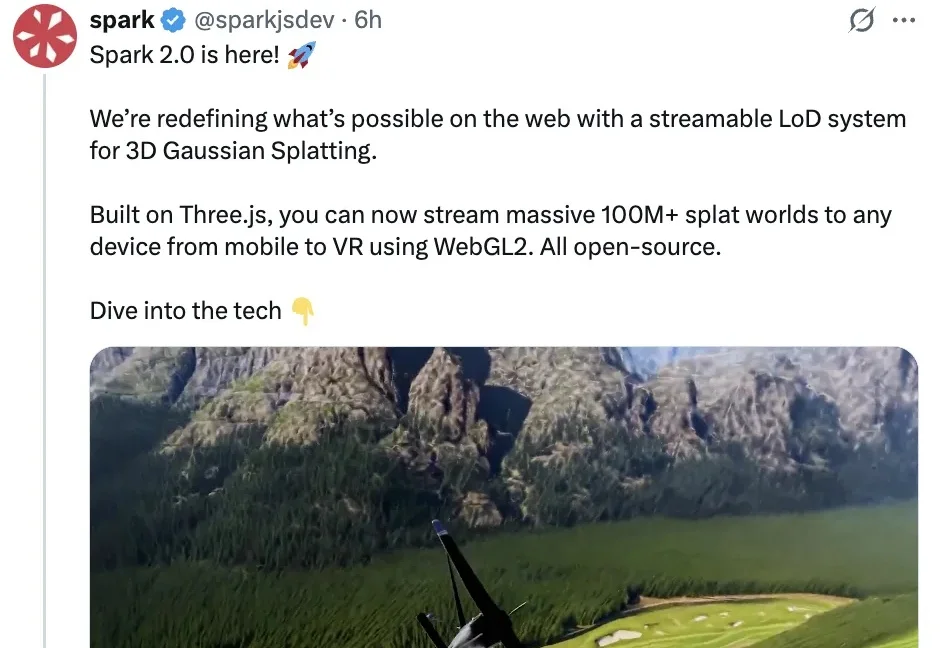
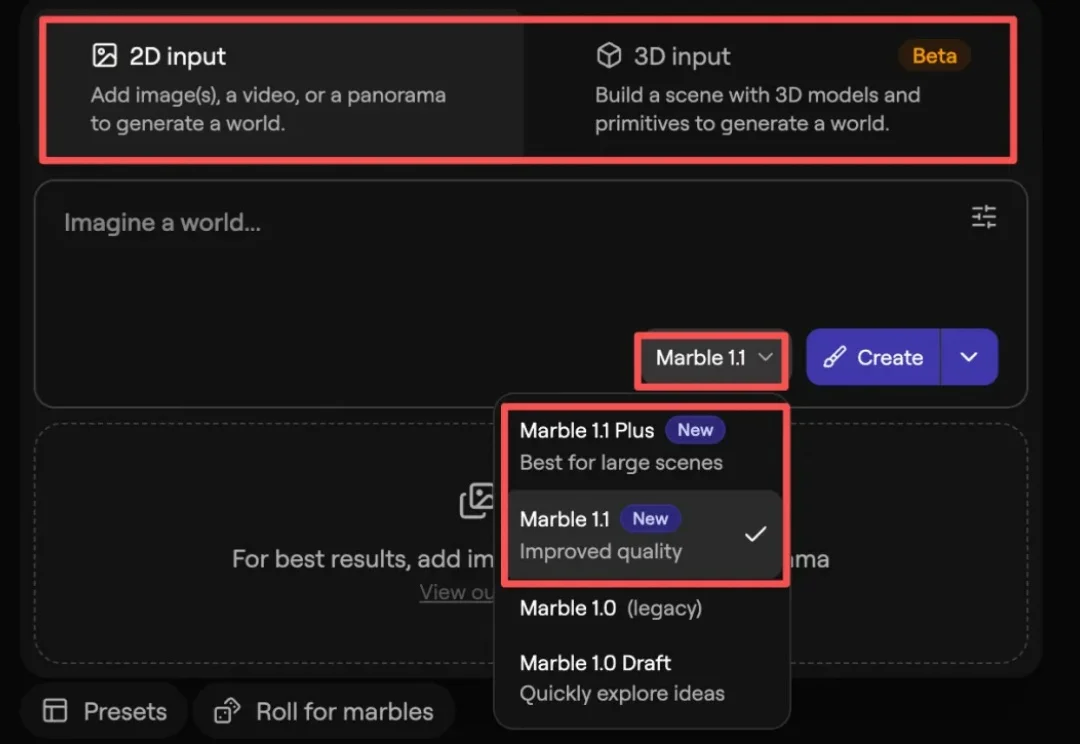
距离新模型Marble 1.1&1.1-Plus发布不到一个周,李飞飞空间智能独角兽World Labs再度传来新消息—— 开源3D高斯溅射渲染引擎Spark 2.0。
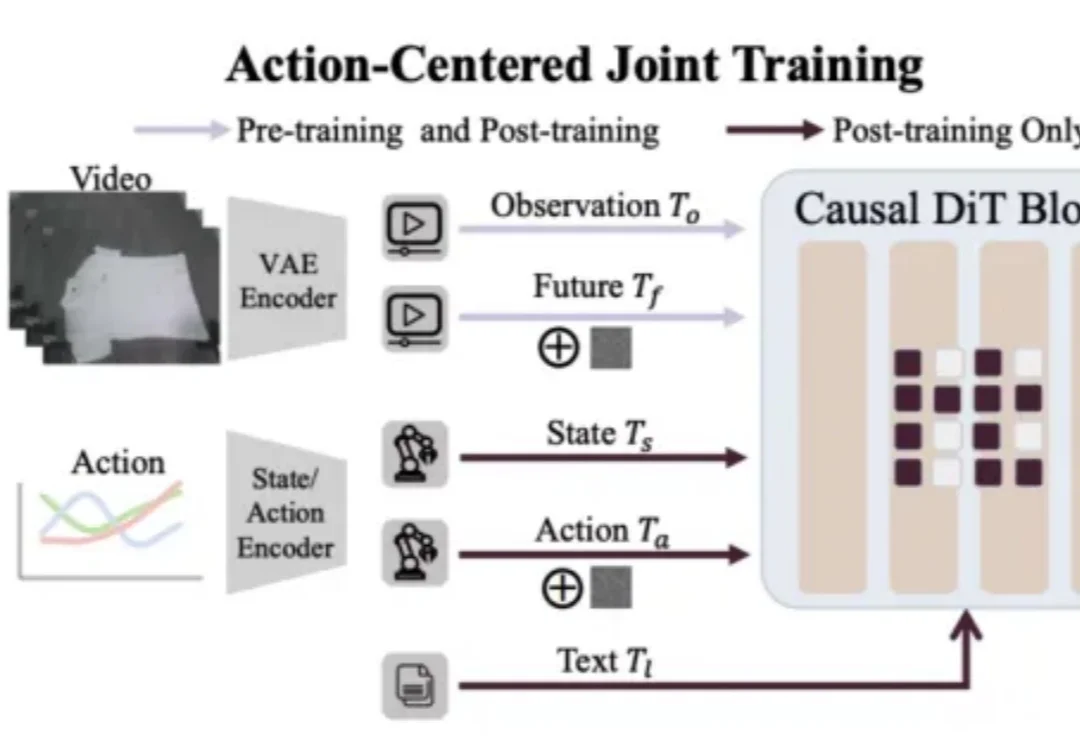
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。

小红书AI平台团队刚刚开源了Relax——一个为全模态数据、Agentic工作流和大规模异步训练协同设计的现代RL训练引擎!实测全异步Off-Policy模式相比共卡On-Policy吞吐提升76%,相比veRL的全异步实现提升20%!
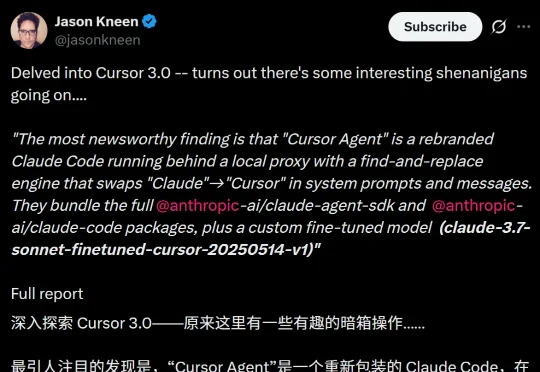
新鲜大瓜!Cursor 3.0实锤套壳Claude Code。当Cursor 3.0被开发者一层层拆开,大家才猛然发现:这场翻车真正刺痛行业的,不是它用了Claude,而是它试图把别人的大脑,包装成自己的灵魂。

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。
李飞飞的 World Labs 又更新模型了。