
AI能自己打红警了!经济拉满零交战惨遭打脸,玩家笑疯
AI能自己打红警了!经济拉满零交战惨遭打脸,玩家笑疯红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。
来自主题: AI资讯
7860 点击 2026-04-29 09:55
 搜索
搜索
红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。
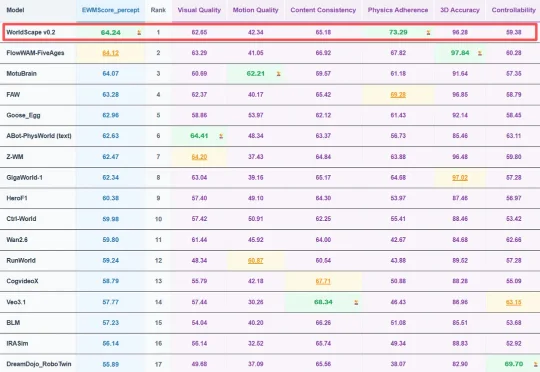
近日,全球具身世界模型权威基准评测 WorldArena 正式更新最新榜单。Manifold AI 流形空间研发的世界模型 WorldScape 0.2,凭借其在物理规律遵循与多源交互理解上的突破取得 WorldArena 榜单全球第一,充分展现了国产世界模型在复杂动态场景生成与具身控制中的高精度、强泛化与物理可信度。与其同场竞技的包括英伟达、谷歌等国外巨头和星动纪元、极佳视界等国内具身智能公司。
Harness(驯马)会成为这个(AI)时代最关键的能力之一。这是小马智行CTO楼天城,在与量子位的对话中,给出的最新判断。在他看来,如今的AI越来越像一匹脱缰野马。它开始学会了「调用」:调用工具、调用skills……因此能通过这些脚手架,自我演进,和人类打配合。

而我们之所以注意到这种玩法,是因为最近一则醒目的消息:3D 打印界扛把子拓竹的模型平台 MakerWorld 迎来了一位新盟友 —— 胡渊鸣创立的 Meshy AI。提起胡渊鸣,机器之心的读者应该都不陌生。2019 年,我们就开始报道他的计算机图形库「太極」。2020 年,他因用 99 行代码复刻《冰雪奇缘》积雪物理特效被大众所熟知,登顶社交媒体热搜。如今,多年过去,他已经在新的赛道领跑。

允中 发自 凹非寺 量子位 | 公众号 QbitAI 这两天,大家伙朋友圈是不是被GPT-Image-2刷屏了? 文字渲染精准、高密度的信息图,复杂布局和美学UI一次到位,真实感爆棚。 连社交媒体截图
作者|周一笑 邮箱|zhouyixiao@pingwest.com 2026 年 3 月 17 日,拓竹科技把 Meshy 6 接进了 MakerWorld 的 MakerLab。一张照片上传上去,两
一款名为 MotuBrain 的神秘世界模型,悄无声息地登上两个国际 benchmark 的榜首,没有任何公司署名。如果只是单榜第一,这件事或许并不稀奇。但问题在于,它同时拿下的,是两个几乎代表行业「两个极点」的榜单:一个是衡量世界模型「是否真正理解和预测现实世界」的 WorldArena

今年4月,具身智能领域发生了一件看起来不大、但意味深长的事。
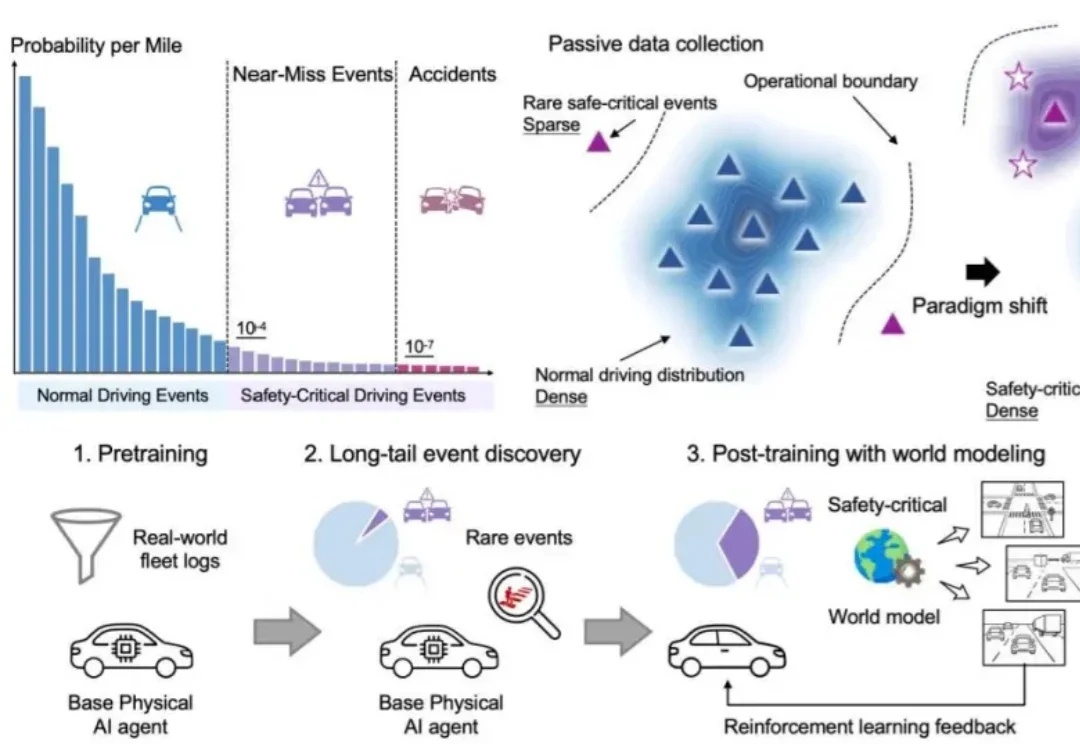
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。

今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖GUI智能体在线RL训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用ClawGUI-RL训练,用ClawGUI-Eval评测,用OpenClaw-GUI部署,端到端验证。