

强化学习之父当头一棒:RL版「苦涩的教训」来了!通往ASI,绝非靠人类数据
强化学习之父当头一棒:RL版「苦涩的教训」来了!通往ASI,绝非靠人类数据强化学习之父Richard Sutton和DeepMind强化学习副总裁David Silver对我们发出了当头棒喝:如今,人类已经由数据时代踏入经验时代。通往ASI之路要靠RL,而非人类数据!
来自主题: AI技术研报
9745 点击 2025-04-21 10:52
强化学习之父Richard Sutton和DeepMind强化学习副总裁David Silver对我们发出了当头棒喝:如今,人类已经由数据时代踏入经验时代。通往ASI之路要靠RL,而非人类数据!
o3编码直逼全球TOP 200人类选手,却存在一个致命问题:幻觉率高达33%,是o1的两倍。Ai2科学家直指,RL过度优化成硬伤。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?

人类生成的数据推动了人工智能的惊人进步,但接下来会怎样呢?

移动GUI自动化智能体V-Droid采用「验证器驱动」架构,通过离散化动作空间并利用LLM评估候选动作,实现了高效决策。在AndroidWorld等多个基准测试中任务成功率分别达到59.5%、38.3%和49%,决策延迟仅0.7秒,接近实时响应。
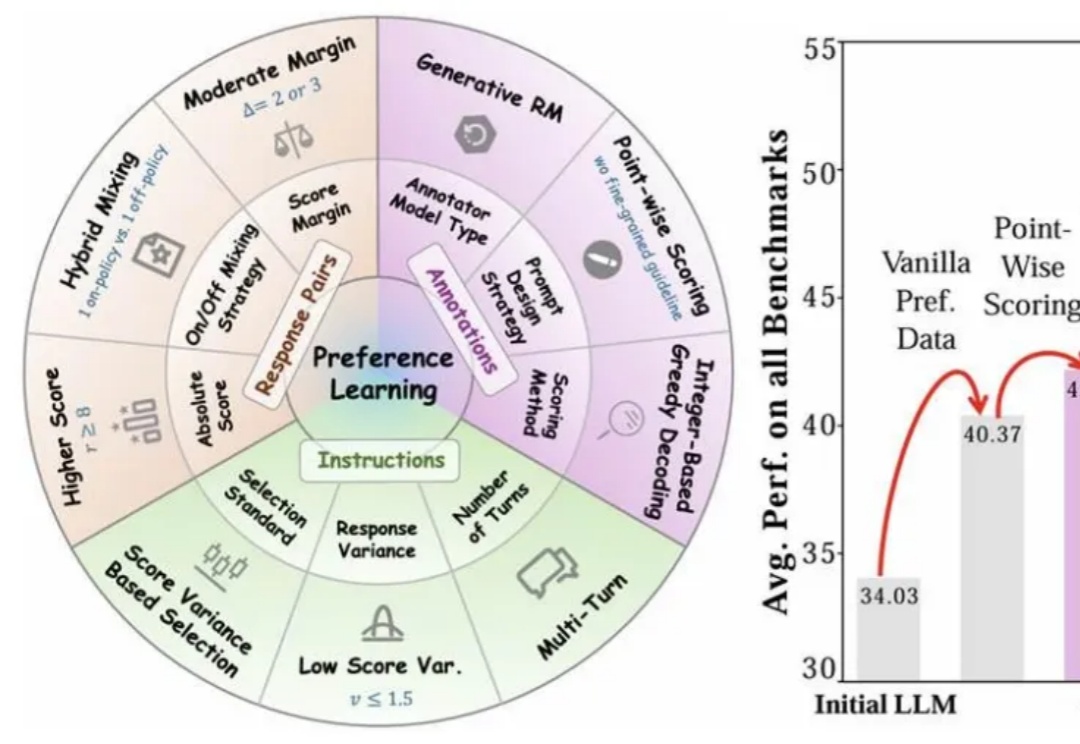
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。

世界模型领域最新进展,要比拼“世界生成”了。
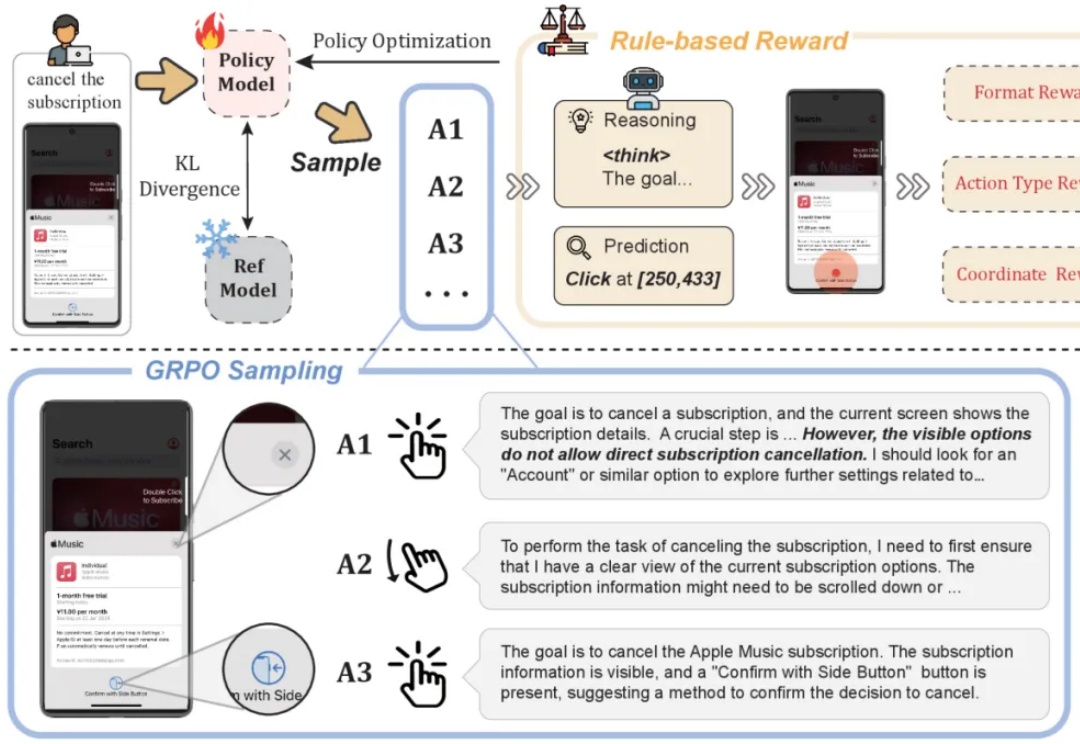
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。
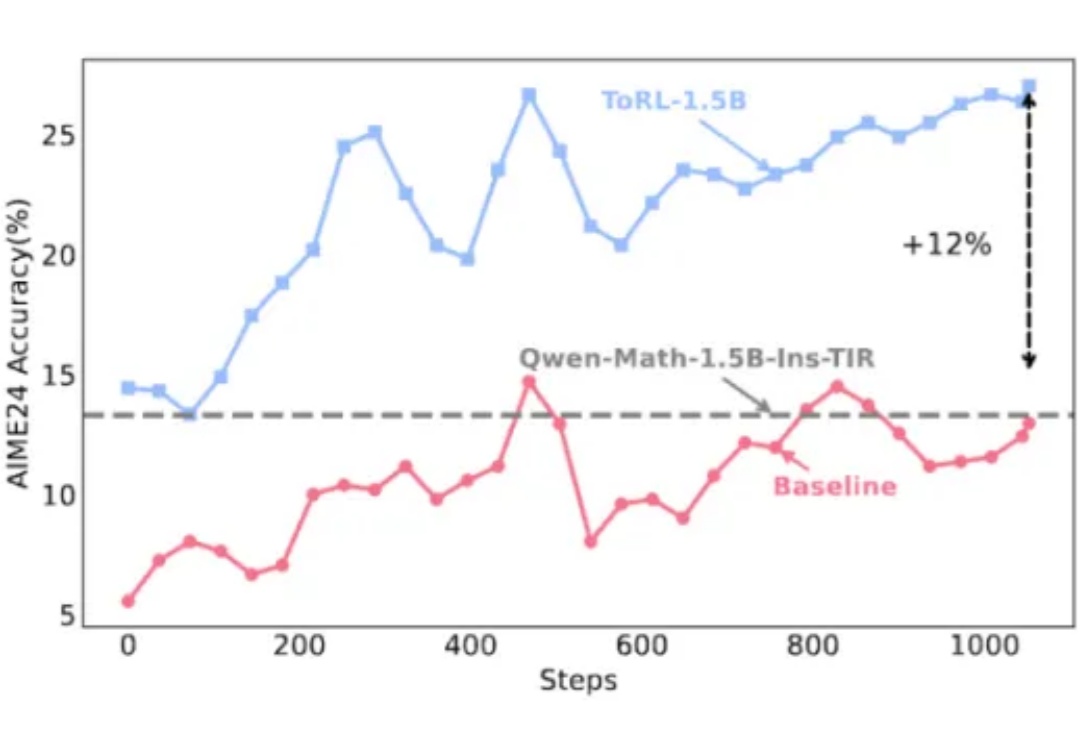
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。