

如何打造TTRL测试时强化学习+Memory的Agent,做经验时代AI的主人。| 最新
如何打造TTRL测试时强化学习+Memory的Agent,做经验时代AI的主人。| 最新AI能像人类一样不断从经验中学习、进化,而不仅仅依赖于人工标注的数据?测试时强化学习(TTRL)与记忆系统的结合正在开启这一全新可能!
来自主题: AI技术研报
9723 点击 2025-04-29 16:24
AI能像人类一样不断从经验中学习、进化,而不仅仅依赖于人工标注的数据?测试时强化学习(TTRL)与记忆系统的结合正在开启这一全新可能!
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
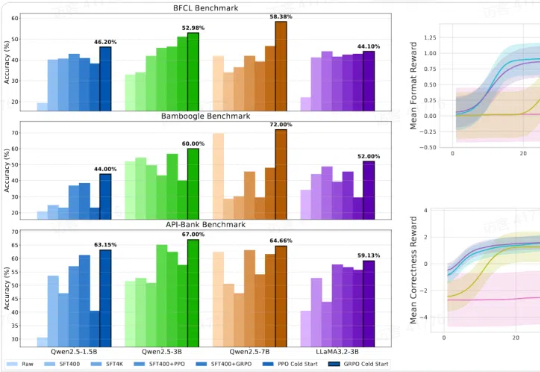
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。

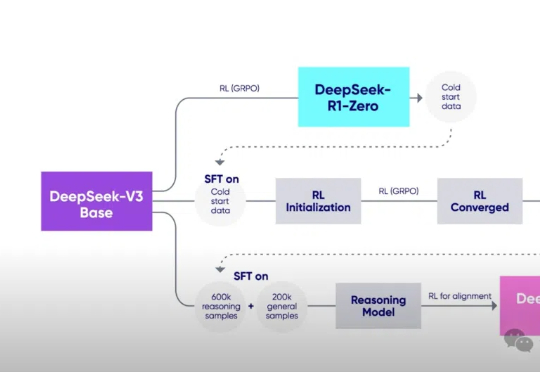
RL + LLM 升级之路的四层阶梯。
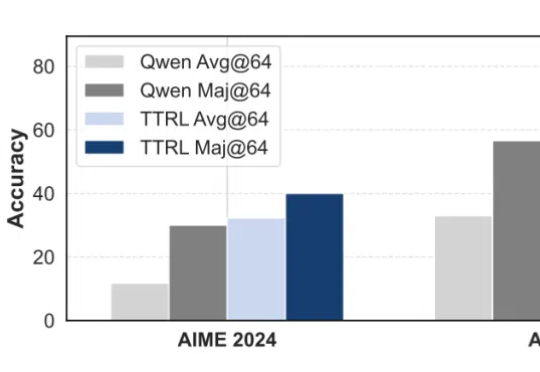
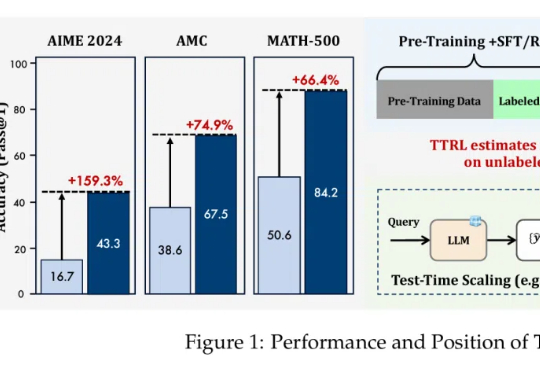
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。

新加坡-麻省理工学院研究联盟、新加坡 A*SRL 实验室、新加坡国立大学、美国麻省理工学院的联合研究团队,提出了一种结合紫外吸收光谱与机器学习的检测方法,能在 30 分钟内完成细胞培养上清液的微生物污染检测。

Transformer作者Ashish Vaswani团队重磅LLM研究!简单指令:「Wait,」就能有效激发LLM显式反思,表现堪比直接告知模型存在错误。
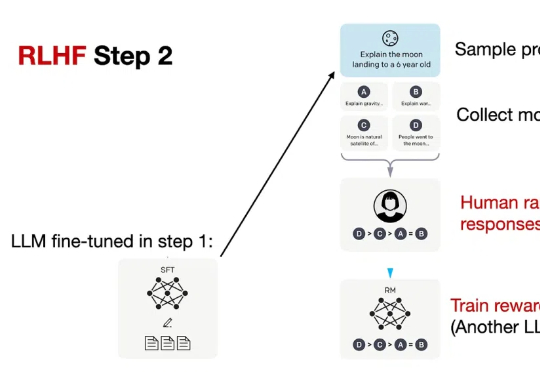
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。