
最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式
最新Agentic Search综述,RL让Agent自主检索,RAG逐渐成为过去式大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。
来自主题: AI资讯
7551 点击 2025-10-25 14:09
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
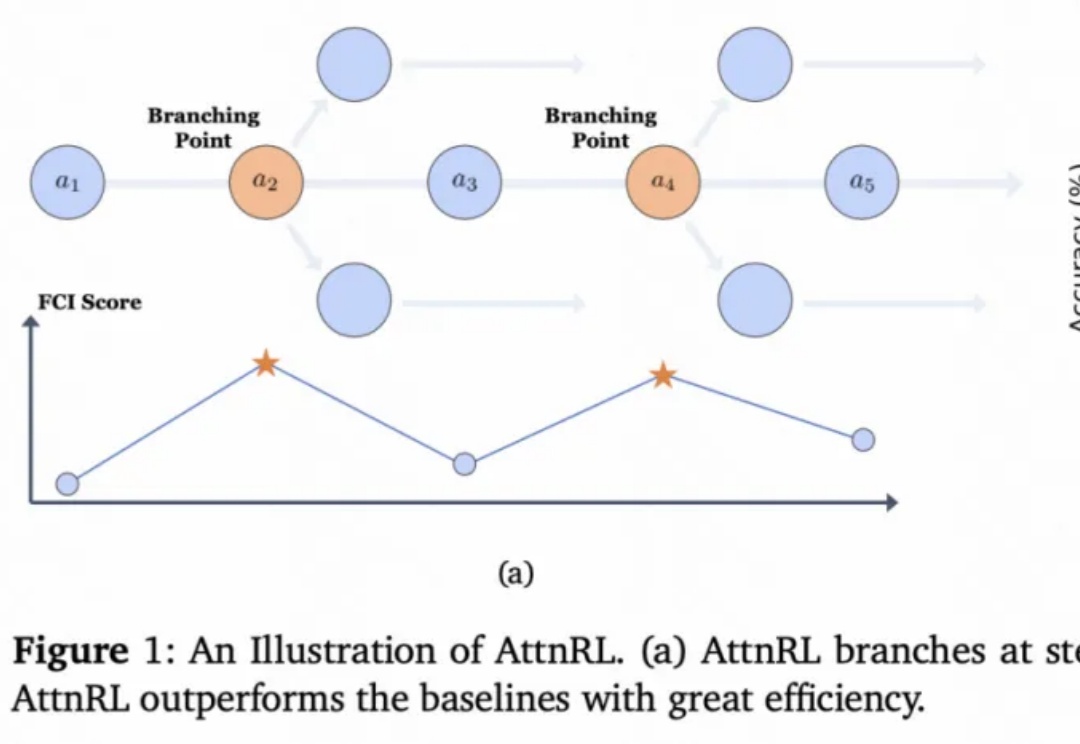
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。
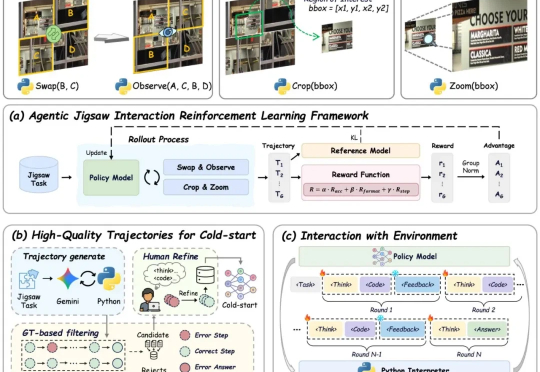
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。

美国麻省理工学院李巨团队在国际顶尖学术期刊Nature上发表了一篇研究论文,展示了一种多模态机器人平台CRESt(Copilot for Real-world Experimental Scientists),通过将多模态模型(融合文本知识、化学成分以及微观结构信息)驱动的材料设计与高通量自动化实验相结合,大幅提升催化剂的研发速度和质量。

在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。

Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。