
港股新贵押注物理AI,乐动机器人打造万亿市场空间的核心基础设施
港股新贵押注物理AI,乐动机器人打造万亿市场空间的核心基础设施物理AI发展到现在,所有玩家都奔着同一个方向使劲: 让机器人「读懂」所处的物理环境。
来自主题: AI资讯
9406 点击 2026-07-01 10:27
 搜索
搜索
物理AI发展到现在,所有玩家都奔着同一个方向使劲: 让机器人「读懂」所处的物理环境。
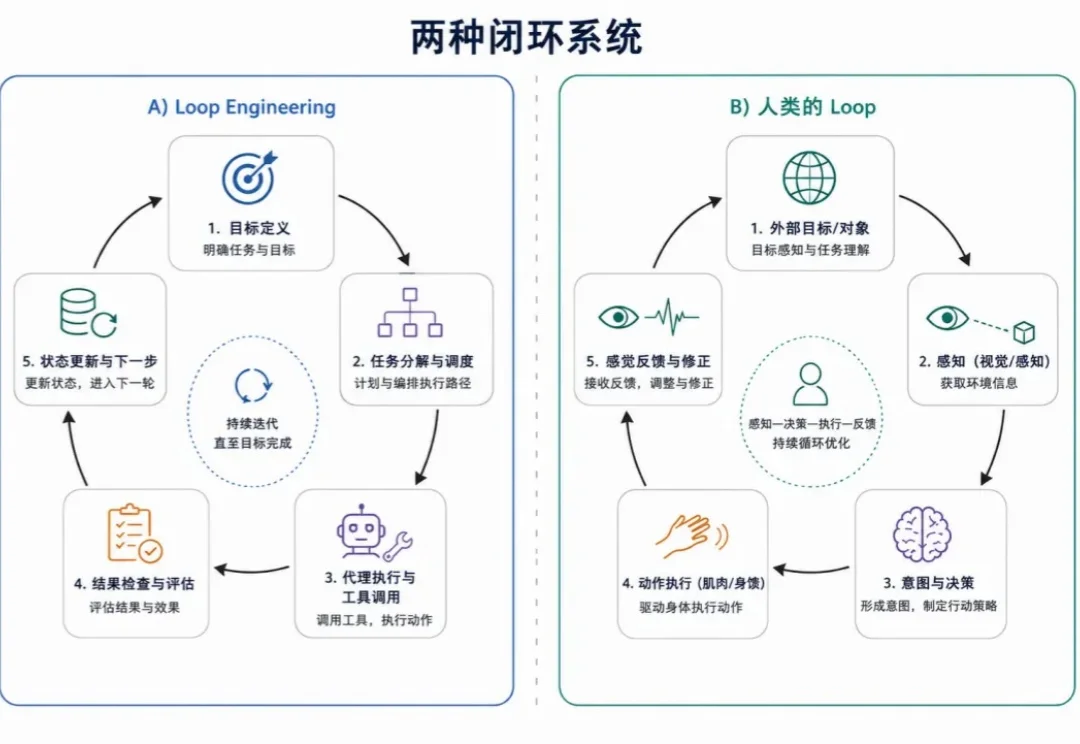
AI 圈最近又热了一个词:Loop Engineering。
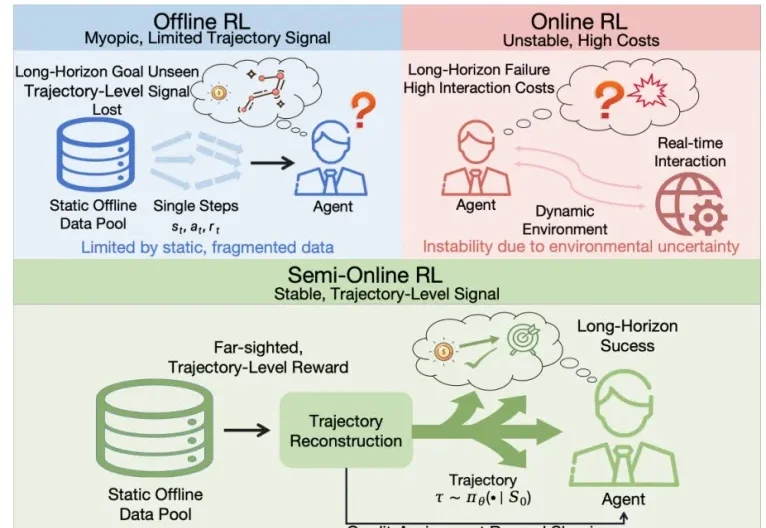
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。
一个模型能模拟7种环境。
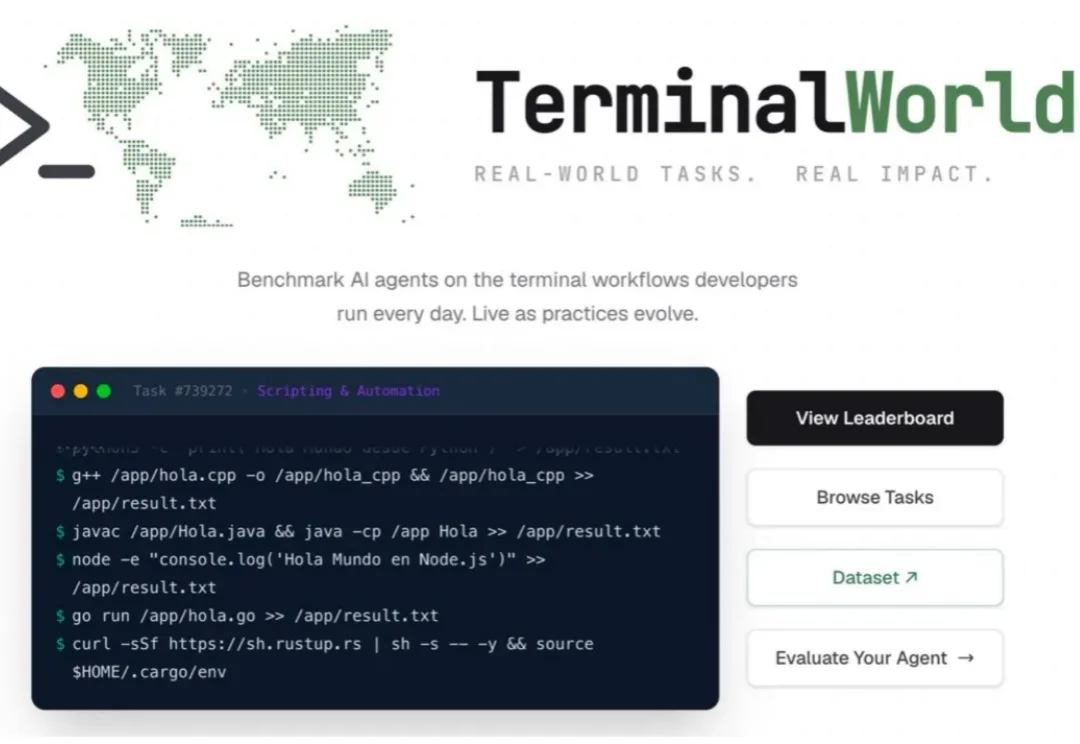
AI Agent 正在重塑软件开发。写代码、修 bug,它的能力肉眼可见地往上涨。但软件开发,从来不止 "写代码" 这一件事。装环境、配依赖、部署服务、编排容器、管理云资源、处理安全策略,这些 "让软件活起来" 的脏活累活,才是真实开发的大头。而它们,几乎都发生在同一个地方:终端。
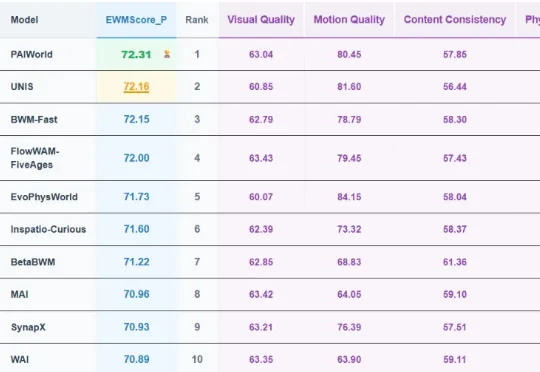
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度
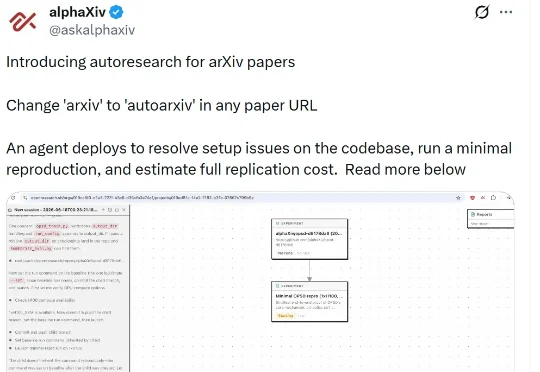
机器之心编辑部 AI 读论文这件事,正在进入下一个阶段。 最近,alphaXiv 推出了一个面向 arXiv 论文的 autoresearch 功能。 它的使用方式非常直接:当用户看到一篇论文时,只需要把论文 URL 里的「arxiv」改成「autoarxiv」,系统就会:

2011 年,Judea Pearl 凭借在因果推理领域的奠基性贡献获得图灵奖。他提出AI必须跨越三层:关联、干预、反事实。2018 年,他在面向大众的著作《The Book of Why》中将这一框架系统化为“因果之梯”。