
AI 让你敢一个人创业,但它也只会顺着你
AI 让你敢一个人创业,但它也只会顺着你先说个数字:2026 年第二季度,通过 Stripe Atlas 注册的美国 C corp 里,63% 是一个人创办的。历史新高。
来自主题: AI资讯
10166 点击 2026-07-01 15:15
 搜索
搜索
先说个数字:2026 年第二季度,通过 Stripe Atlas 注册的美国 C corp 里,63% 是一个人创办的。历史新高。
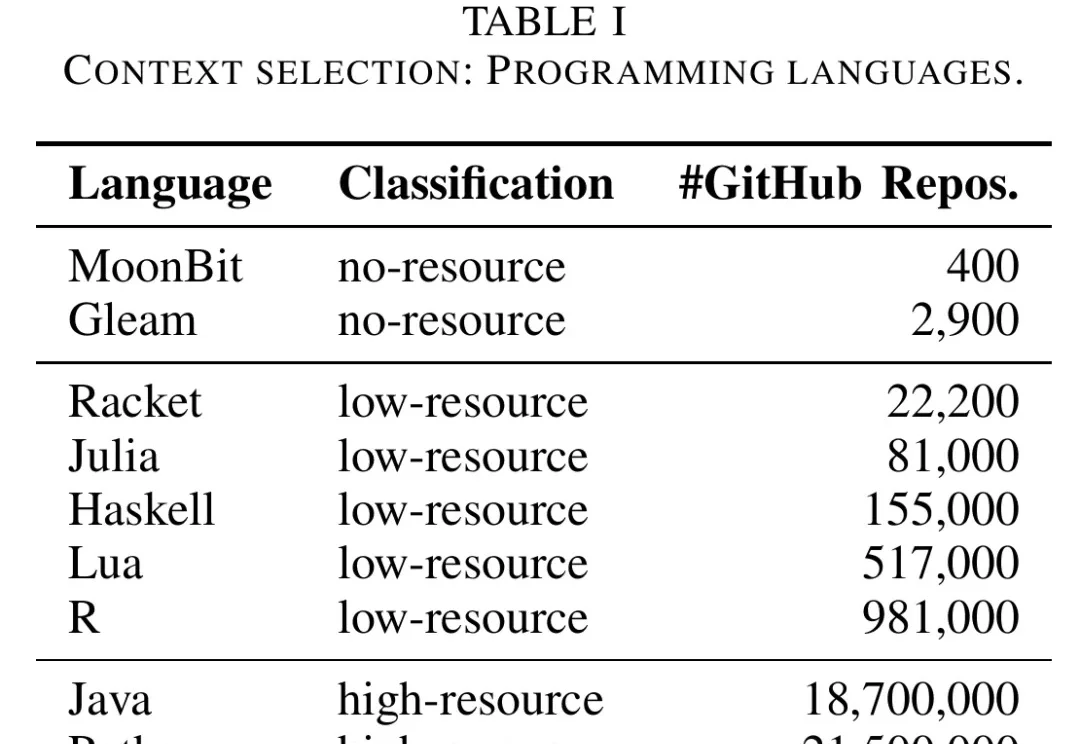
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。
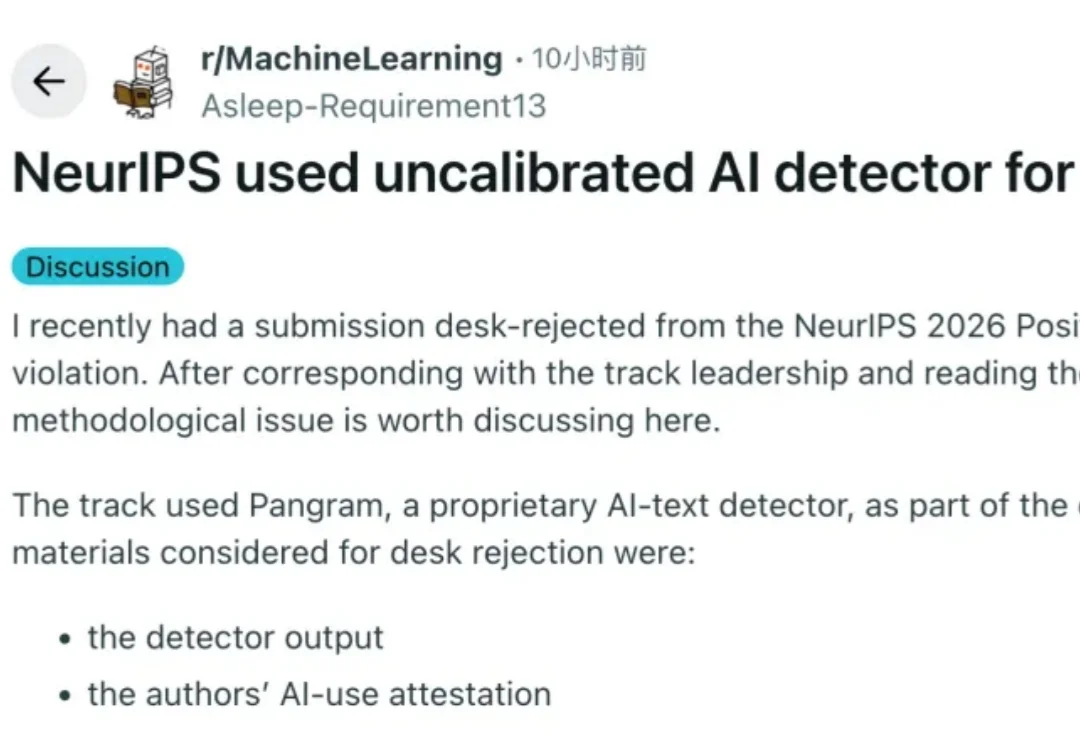
NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。

你有没有想过,作为一个软件创业者,你每个月到底在对账和财务事务上浪费了多少时间?银行流水要确认,薪资系统要对齐,Stripe 里的收款记录要归类,还有各种供应商发票要处理。这些事情不难,甚至可以说很机械,但它们每个月都会悄无声息地吃掉你好几个小时。

LiberAI已于近期连续完成种子轮、天使轮及天使+轮融资,累计金额数亿元人民币,投资方包括真格基金、红杉中国、美团龙珠、顺为资本等一线机构。公司成立于2025年12月,CEO刘松铭是清华特等奖学金获得者,师从清华大学朱军教授,在ICML、NeurIPS等顶会发表多篇一作论文。
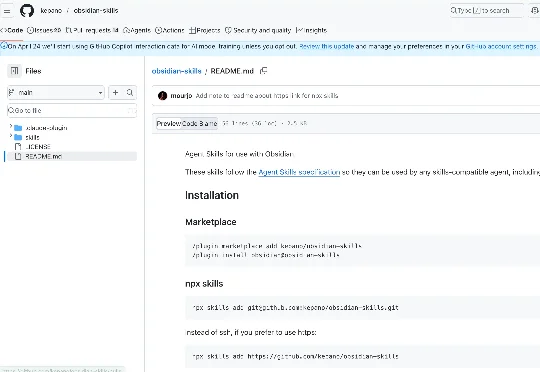
随手打开 GitHub,2026 年的 Agent 项目热榜上有这样一个仓库: • 27,000+ stars,1,800+ forks • 零行 Python,零行 TypeScript,零行 JS • 作者是 Obsidian 的 CEO 本人,kepano • 整个仓库就是 5 个 Markdown 文件

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」

刚刚的消息,Cloudflare 联合 Stripe 发布了一份新协议,Agent 现在可以独立成为 Cloudflare 的客户。它能自己创建账户、订阅付费方案、注册域名、拿到 API token,然后直接部署代码

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。