从「会说」迈向「会做」,LLM下半场:Agentic强化学习范式综述
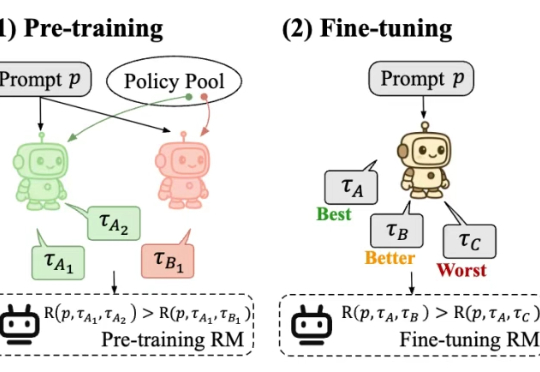
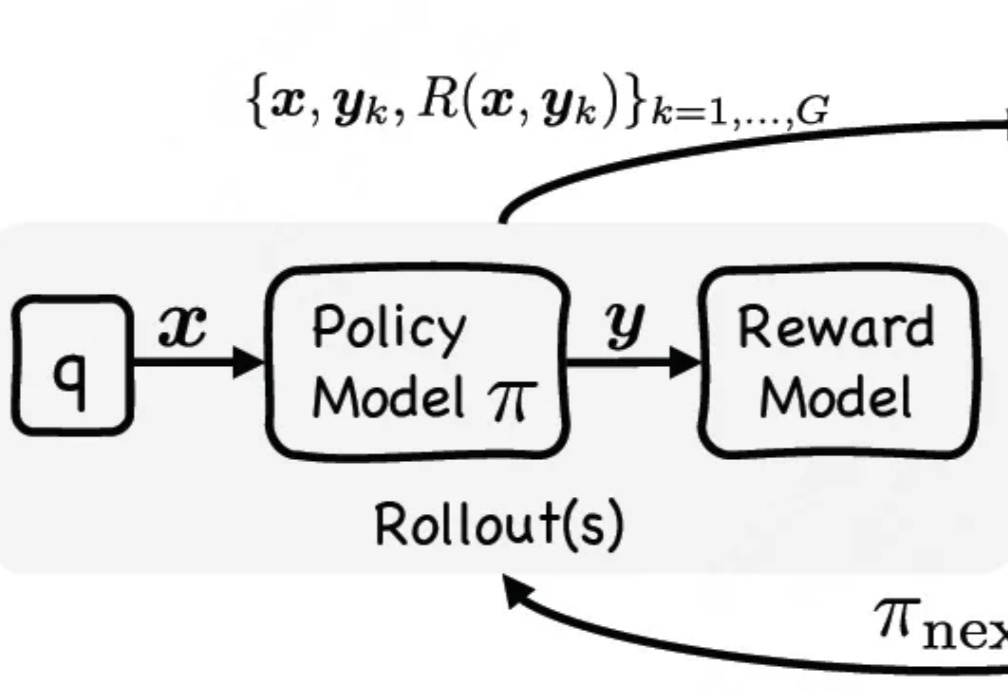
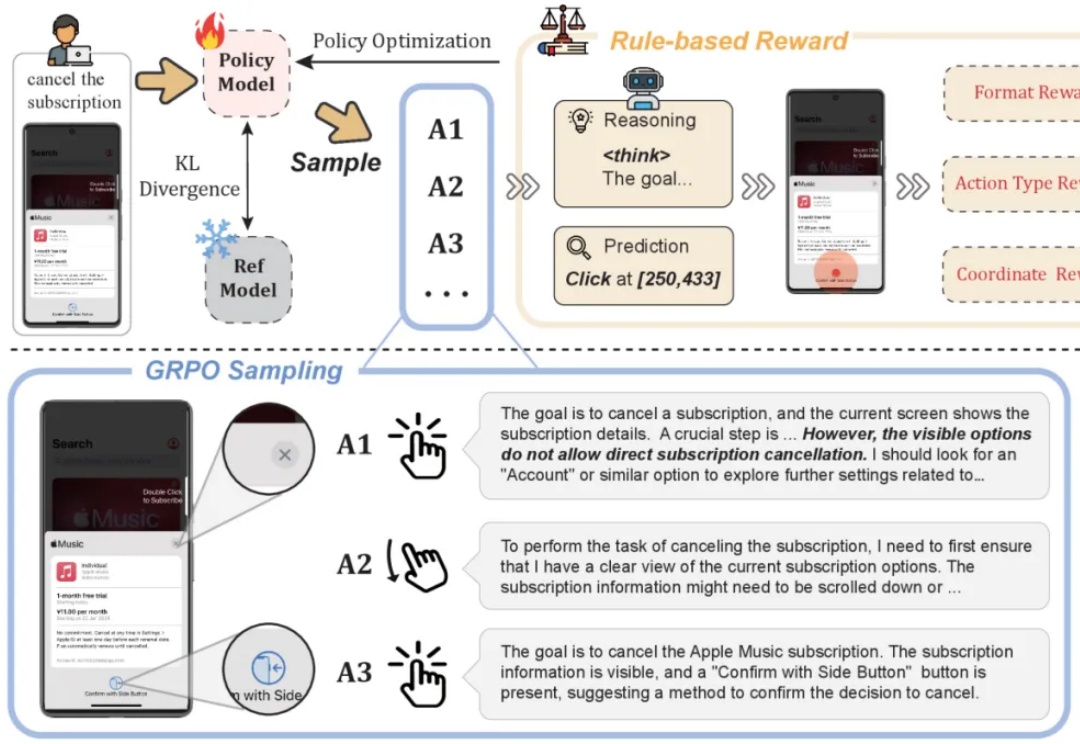
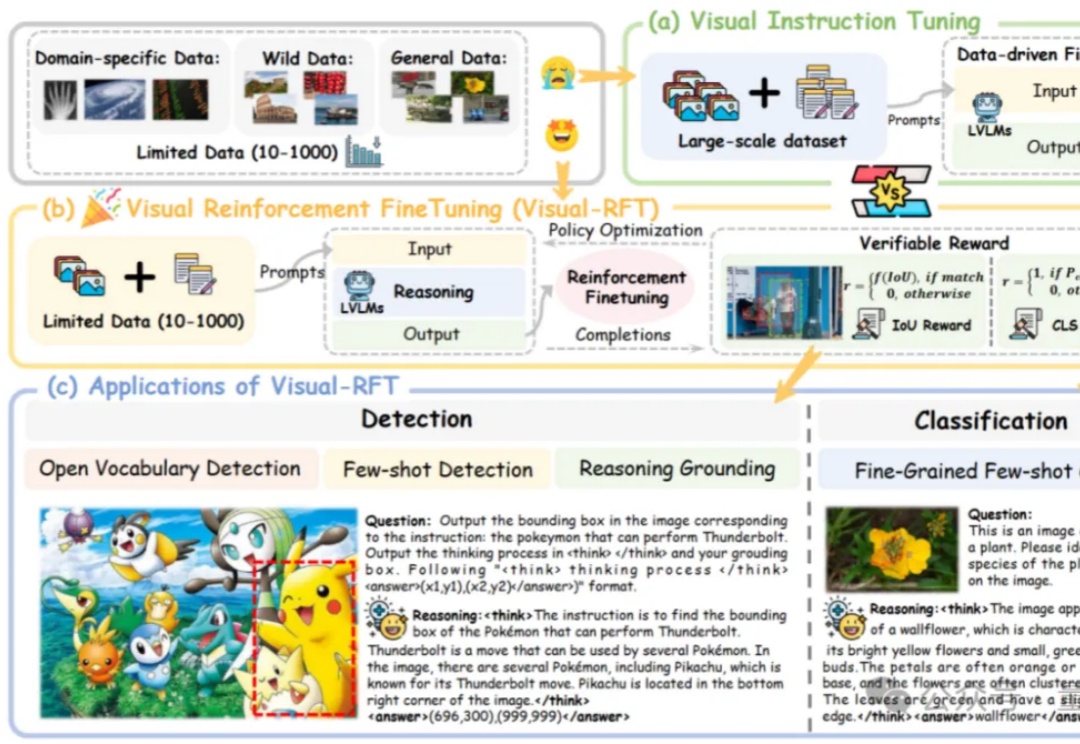
从「会说」迈向「会做」,LLM下半场:Agentic强化学习范式综述过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
来自主题: AI技术研报
9898 点击 2025-09-09 10:49