

深夜突袭,阿里Qwen3登顶全球开源王座!暴击DeepSeek-R1,2小时狂揽17k星
深夜突袭,阿里Qwen3登顶全球开源王座!暴击DeepSeek-R1,2小时狂揽17k星阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
来自主题: AI资讯
11200 点击 2025-04-29 08:49
阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
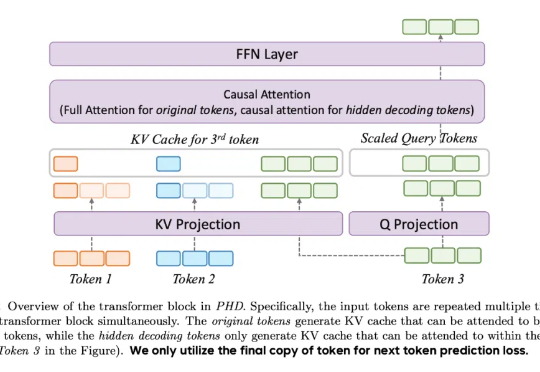
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
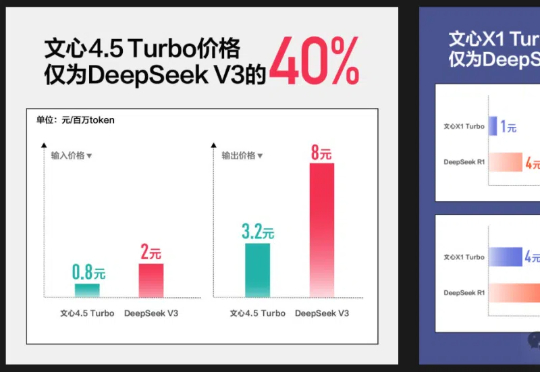
百度文心大模型X1 Turbo正式发布了。这个基于4.5 Turbo的深度思考模型,效果领先DeepSeek-R1、V3,且价格仅为R1的25%!而文心4.5 Turbo在低价的同时,多模态能力更是让人出乎意料。
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。

什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。
昆仑万维Skywork-R1V 2.0版本,开源了!这一次,它的多模态推理实现了再进化,成为最强高考数理解题利器,直接就是985水平。而团队也大方公开了各项技术秘籍,亮点满满。可以说,R1V 2.0已成为团队AGI之路上的又一里程碑。
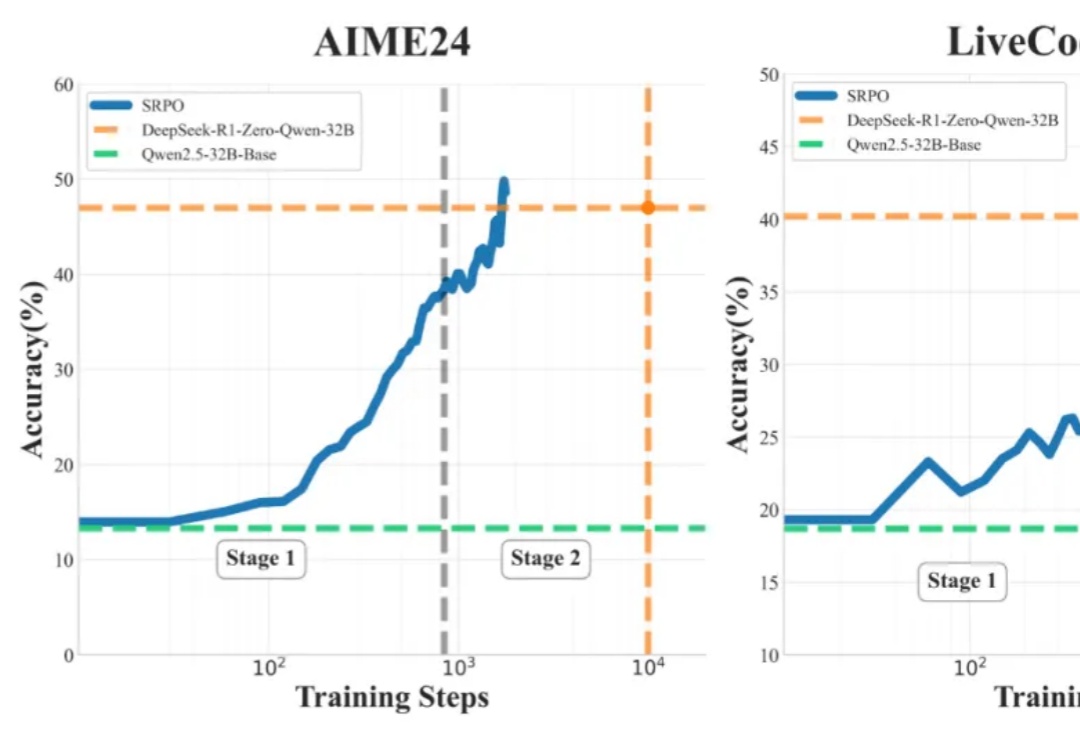
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

2025开年伊始,从1月DeepSeek R1发布引发新一轮国产大模型技术爆发,到3月Manus横空出世启动内测打开AI智能体话题热度,从底层基础设施到终端产品应用,从产业深耕提升纵深能力到产品创新形成差异化竞争优势,无论是技术能力还是商业模式,国产AI都处于全球领先水平。海外无论是政策环境还是供需关系,均从内外部双轮驱动国产AI出海蓄势待发。