
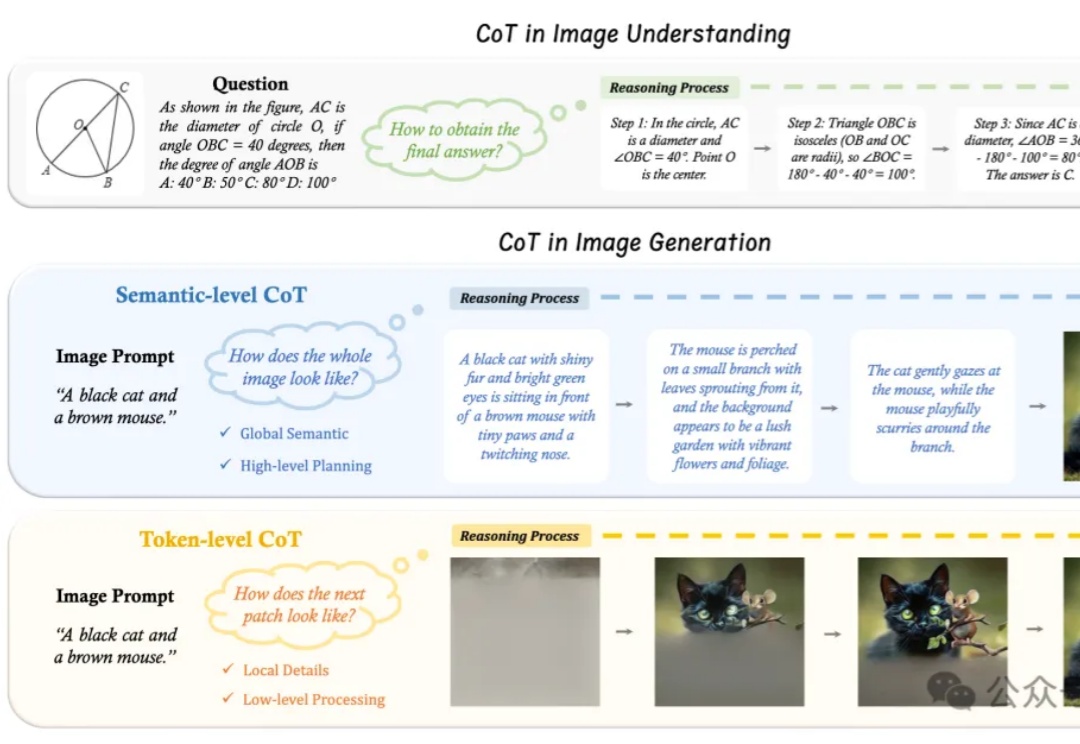
文生图进入R1时代:港中文MMLab发布T2I-R1,让AI绘画“先推理再下笔”
文生图进入R1时代:港中文MMLab发布T2I-R1,让AI绘画“先推理再下笔”“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
来自主题: AI技术研报
8944 点击 2025-05-13 15:02
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
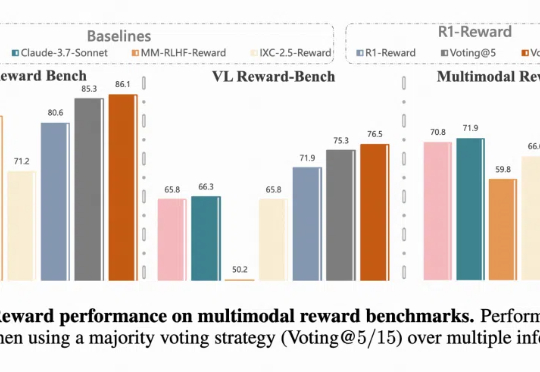
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。

近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!
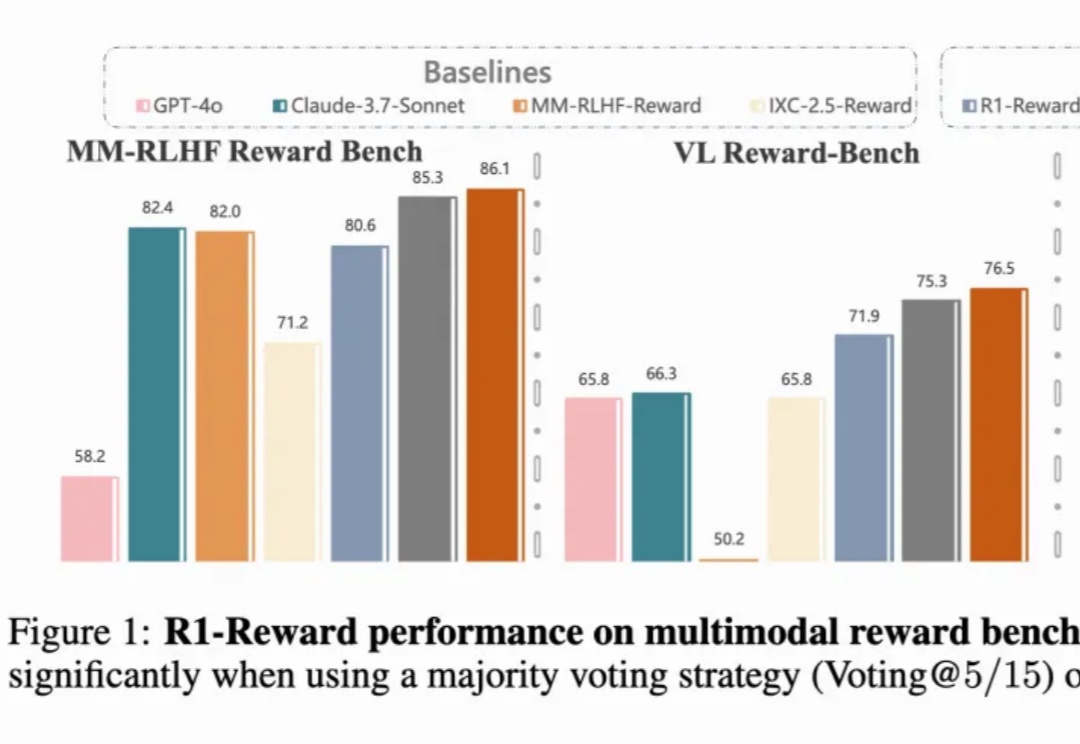
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

近日,阿里云通义点金团队与苏州大学携手合作,在金融大语言模型领域推出了突破性的创新成果:DianJin-R1。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
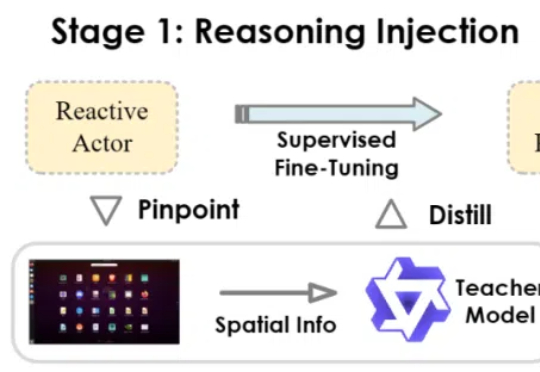
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。