阿里又一个王炸!Qwen3.5-Omni 全模态硬核实测
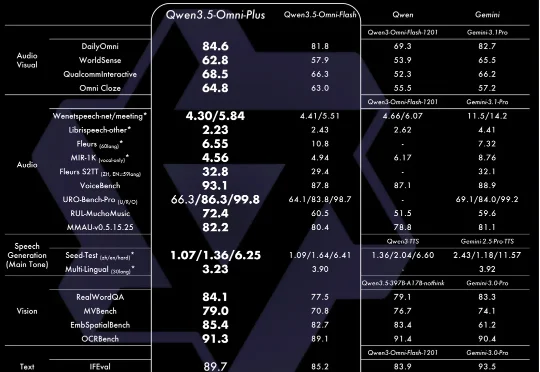
阿里又一个王炸!Qwen3.5-Omni 全模态硬核实测阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
来自主题: AI资讯
9951 点击 2026-03-31 11:20
 搜索
搜索
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
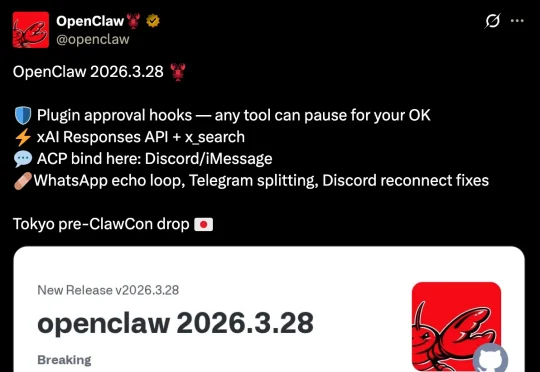
今天,OpenClaw 直接推送了最新的 3.28 版本。这次更新的内容也是格外丰富,简直是底层能力的全面大解放。简单挑几个跟日常体验关系最大的。Qwen 模型正式迁移到了 Model Studio,直接走新的认证选项,干净利落。
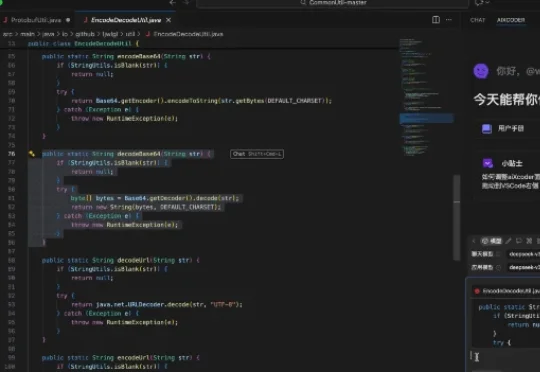
硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度
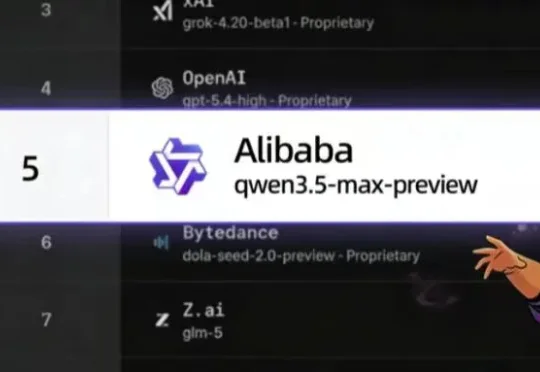
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。
最近几年,大模型赛道好不热闹。

千问(Qwen)技术负责人林俊旸在X上宣布离职24小时后,阿里高层火速批准了他的离职邮件。如果单从时间节点看,林俊旸的离开,很容易被解读为一次“模型迭代失利后的调整”。 过去一年,Qwen模型迭代频繁
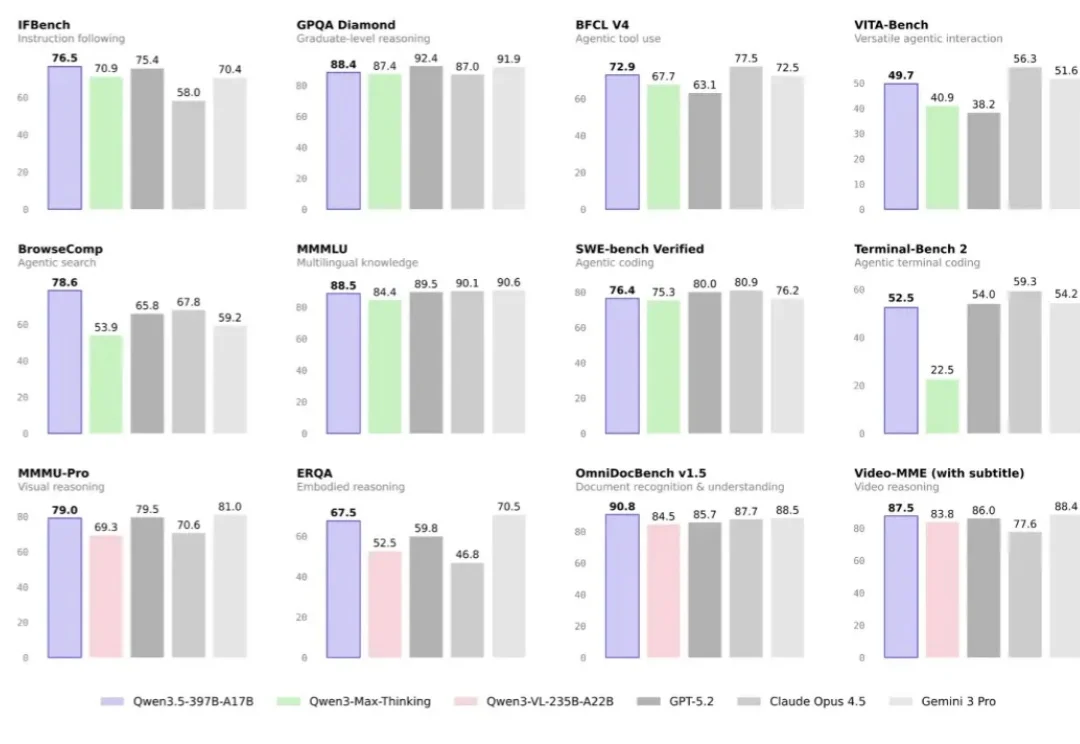
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。

离职的消息最沸沸扬扬的时候,Qwen 团队的核心负责人林俊旸在朋友圈发了两句话:

林俊旸的名字刷屏了一整天。

北京时间3月4日下午约13:00,通义实验室紧急召开了All Hands会议,阿里集团CEO吴泳铭向千问员工坦诚表示。12个小时前(北京时间3月4日凌晨0点11分),阿里千问大模型技术负责人林俊旸在X上突然宣布离职——林俊旸是阿里AI开源模型的核心推手,也是阿里最年轻的P10之一——行业一片哗然之时,Qwen的部分成员也无法接受团队灵魂人物的突然出走。