
「双线实测」Qwen 3.6-Plus,Agentic Coding 已经这么能“扛活儿”了?
「双线实测」Qwen 3.6-Plus,Agentic Coding 已经这么能“扛活儿”了?全球最强编程模型,中国造。
来自主题: AI技术研报
8024 点击 2026-04-16 12:25
 搜索
搜索
全球最强编程模型,中国造。
昨天我发现 Qwen3.6“倒反天罡”。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。

Gemma4 31B的发布,在开源模型社区引发了巨大的关注。面对这款由谷歌DeepMind于2026年4月2日 推出的重磅模型,很多技术团队和本地部署玩家都在问同一个问题:Gemma4的出现,到底是在开辟一条新的本地部署路线,还是只是给高端玩家多了一个可选项?我们到底需不需要把现有的Qwen3.5 27B工作流整体迁移过去?

2026 年,阿联酋哈利法大学的邹航博士和他所在的团队,做出了全世界第一个射频大模型,名字叫 RF GPT。这个模型能直接看懂无线信号,就像 GPT 4o 能看懂图片、Qwen2 Audio 能听懂声音一样。你把无线信号扔给它,它不仅能告诉你这里面有几种信号、分别是什么技术,还能分析出有没有信号在打架、哪个是 5G 哪个是蓝牙、甚至能数出来 WiFi 网络里有多少个用户同时在用。

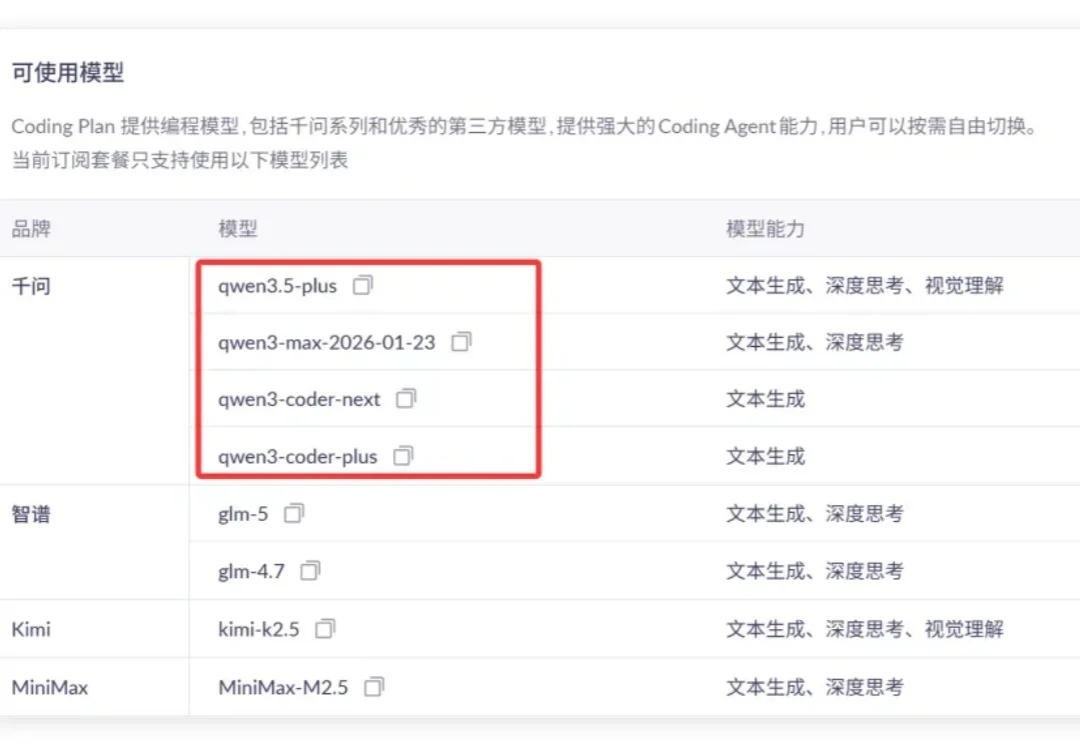
本报告基于XSCT Arena平台,对 Qwen3.6-Plus-Preview(阿里云,2026-04-02 发布)在文字能力(xsct-l)、网页生成(xsct-w)、Agentic 任务(xsct-a)三大场景下的表现进行系统评测,并与Claude Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro、Kimi K2.5、
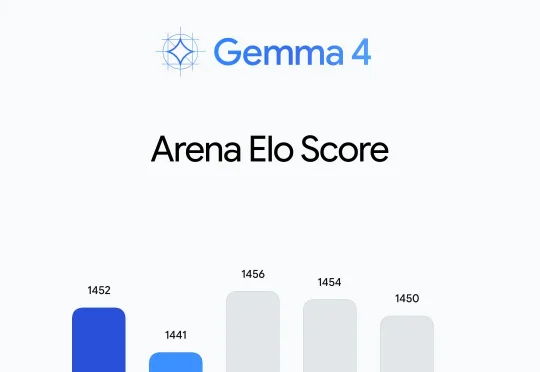
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。

什么这code那code,先别code了,因为—— 中国最强编程模型来了!
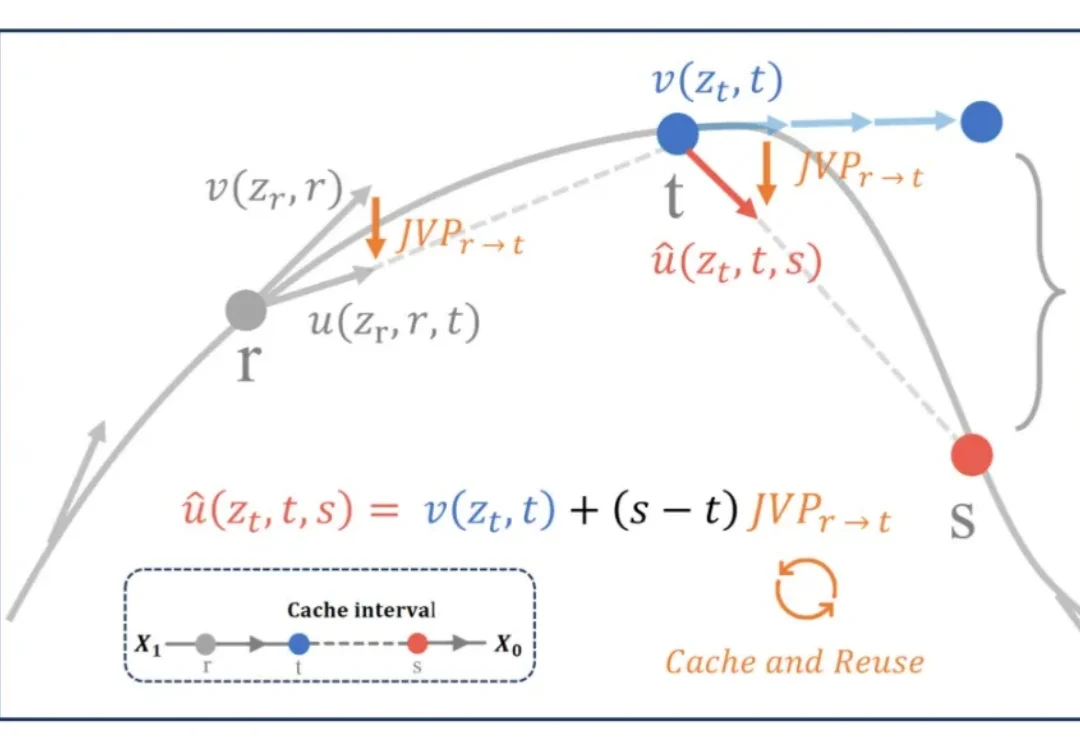
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。

林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。 这不是第一个试图「什么都做」的模型。过去两年,多模态是所