
如何自动优化领域任务的提示词?用EGO-Prompt|NeurIPS 2025
如何自动优化领域任务的提示词?用EGO-Prompt|NeurIPS 2025大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。
来自主题: AI技术研报
8686 点击 2025-11-07 10:52
 搜索
搜索
大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。
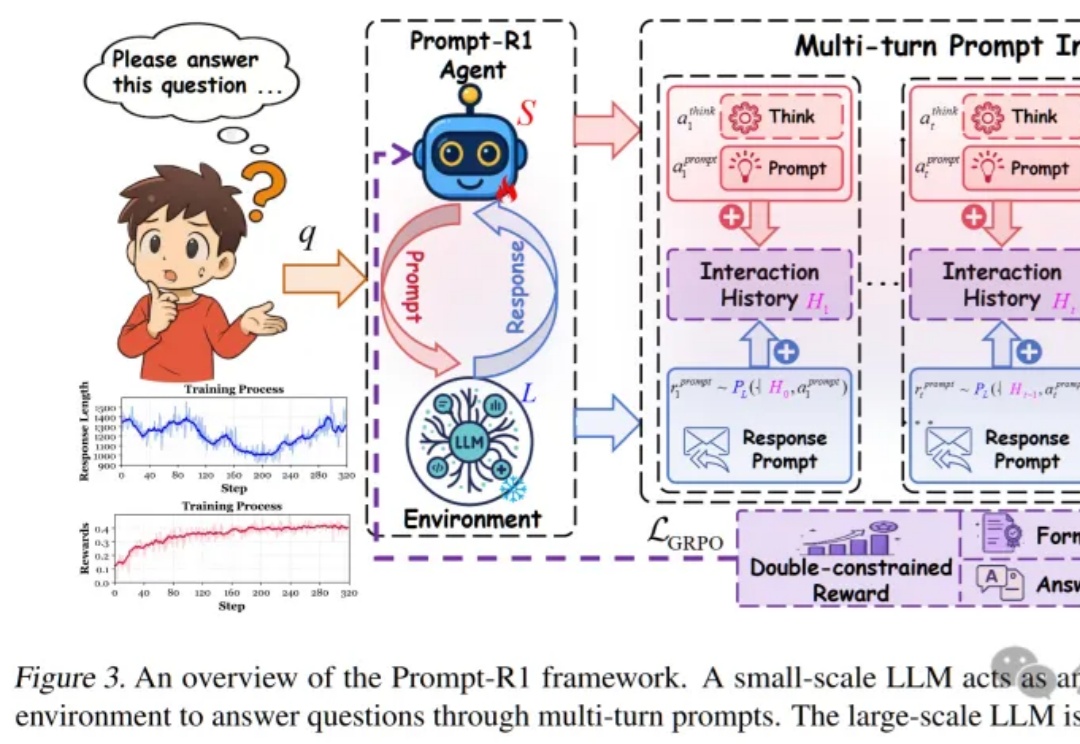
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。

十月,《纽约时报》发表了题为《The A.I. Prompt That Could End the World》(《那个可能终结世界的 AI 提示词》)的文章。作者 Stephen Witt 采访了多位业内人士:有 AI 先驱,图灵奖获奖者 Yoshua Bengio;以越狱测试著称的 Leonard Tang;以及专门研究模型欺骗的 Marius Hobbhahn。

近日刚好得了空闲,在研读 Anthropic 官方技术博客和一些相关论文,主题是「Agent 与 Context 工程」。2025 年 6 月以来,原名为「Prompt Engineering」的提示词工程,在 AI Agent 概念日趋火热的应用潮中,
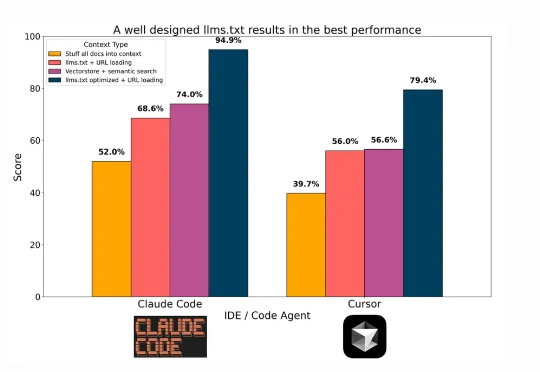
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
那边OpenAI的Sora2还没全面开放,这边国内团队已经上线了自己的“特色打法”。 清华特奖选手创办的Sand.ai,上线了音画同步视频模型GAGA-1。
![苹果盯上Prompt AI, 不是买产品,是要伯克利团队的[视觉大脑]](https://www.aitntnews.com/pictures/2025/10/15/ca7bf835-a97f-11f0-88f9-fa163e47d677.jpg)
根据外媒 CNBC 消息,苹果公司正和计算机视觉领域的初创企业 Prompt AI,推进收购事宜的 “最后阶段谈判”。

写给正在落地 AI 产品的工程师。一些代码直接可改造复用;另一些,是我踩坑后的经验之谈。
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
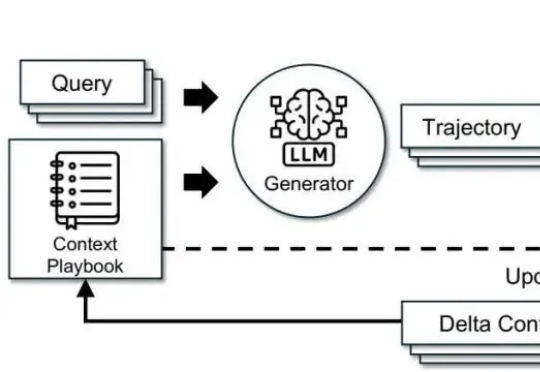
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。