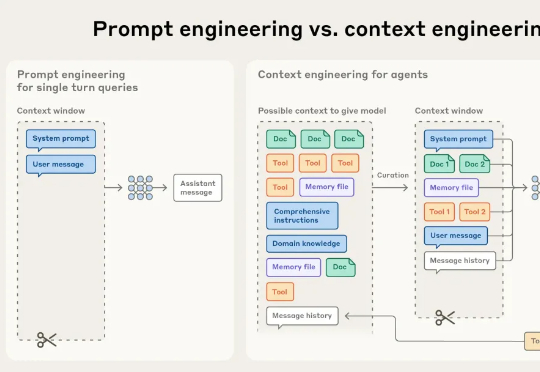
别卷 Prompt 了,上下文工程正在淘汰你
别卷 Prompt 了,上下文工程正在淘汰你Hi,返工早上好。 我是洛小山,和你聊聊 AI 行业思考。 AI Agent 应用的竞争逻辑,正在发生根本性变化。 当许多团队还在死磕提示词优化(PE 工程)时,一些优秀团队开始重心转向了上下文工程
来自主题: AI技术研报
8218 点击 2025-10-09 11:59
 搜索
搜索
Hi,返工早上好。 我是洛小山,和你聊聊 AI 行业思考。 AI Agent 应用的竞争逻辑,正在发生根本性变化。 当许多团队还在死磕提示词优化(PE 工程)时,一些优秀团队开始重心转向了上下文工程

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。
时薪900美元的AI工程师正成为咨询界新贵,直接挑战麦肯锡等传统巨头。面对高达95%的企业AI项目失败率,传统MBA式顾问空有战略却难落地。为此,Hasura推出了一种新型「AI工程师顾问」应运而生,他们不仅能提供策略,更能亲手编码、部署,弥合了从构想到现实的鸿沟。
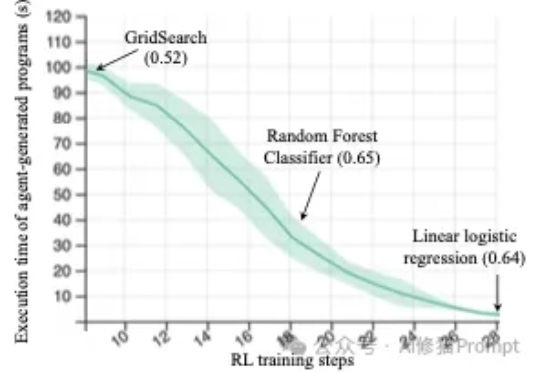
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。

nano banana爆火!网上看到的那些超强效果图是如何生成的呢?谷歌的官方Prompt模板终于来了!赶紧先收藏再说!
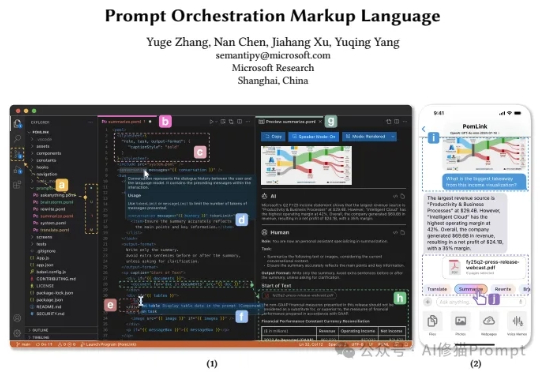
最近来自微软的研究者们带来了一个全新的思路,他们开源发布了POML(Prompt Orchestration Markup Language),它的的解决方案它的核心思想非常直接:为什么我们不能像开发网页一样,用工程化的思维来构建和管理我们的Prompt呢?这个编排语言很类似IBM的PDL
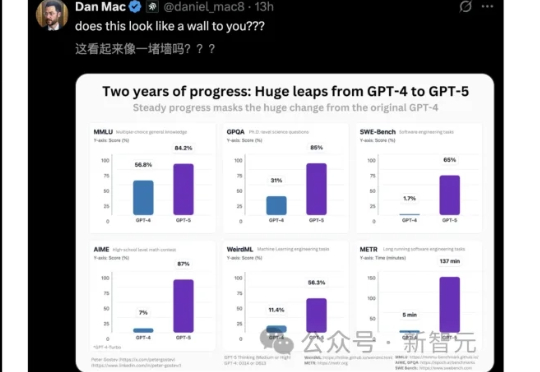
GPT-5发布半月,却被连连吐槽。如今,一张基准与GPT-4对比基准测试图,证明了Scaling Law没有撞墙。七年间,从GPT-1到GPT-5十四个花式Prompt对决,实力差一目了然。

提示词才是AI隐藏的王牌!马里兰MIT等顶尖机构研究证明,一半提示词,是让AI性能飙升49%的关键。