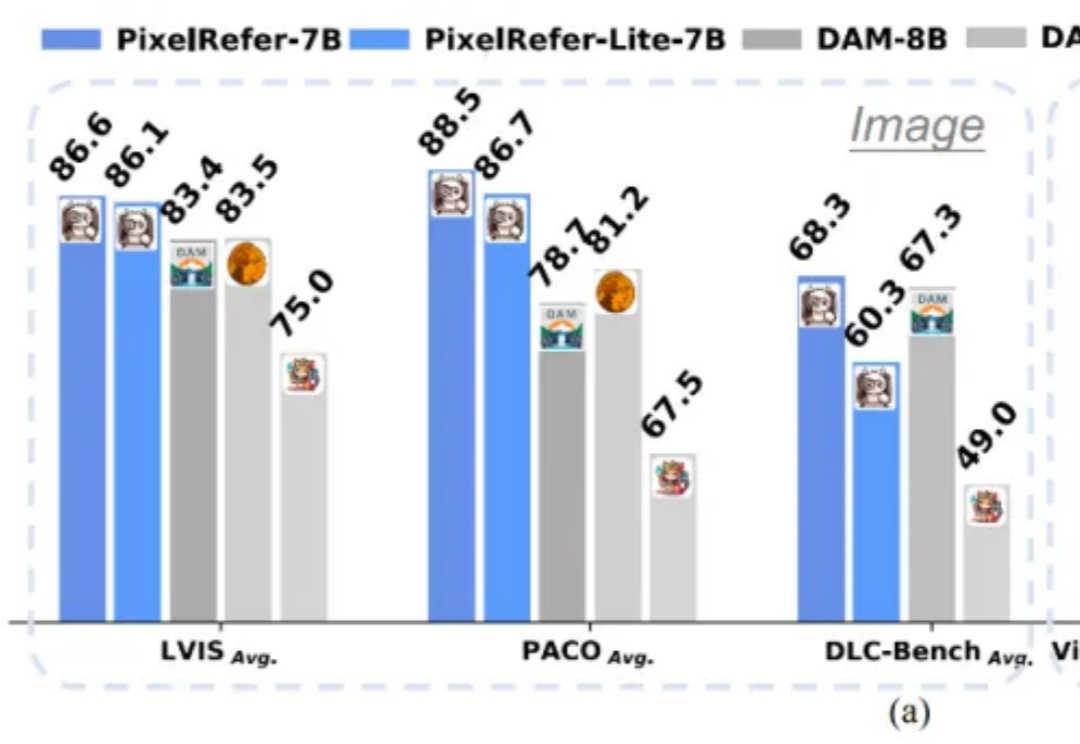
PixelRefer :让AI从“看大图”走向“看懂每个对象” PixelRefer :让AI从“看大图”走向“看懂每个对象” 关键词: AI,模型训练,PixelRefer,AI图像识别 多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。 来自主题: AI技术研报 11647 点击 2025-11-11 09:50
 搜索
搜索