ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」
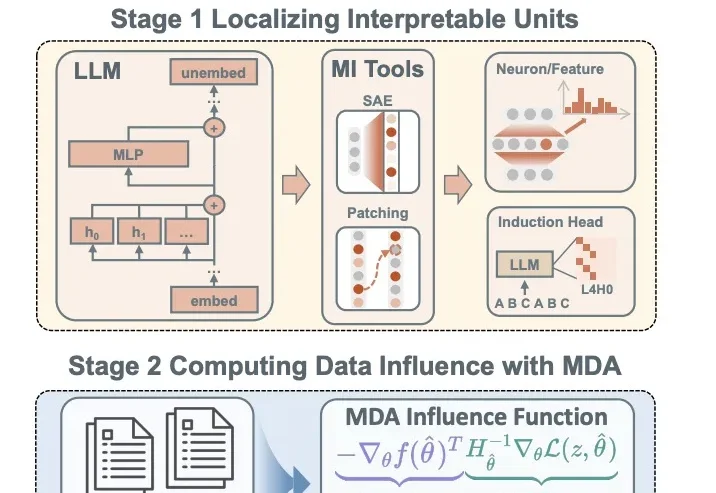
ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
来自主题: AI技术研报
9013 点击 2026-06-29 09:19
 搜索
搜索
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

扩散模型又被玩出新花样了。
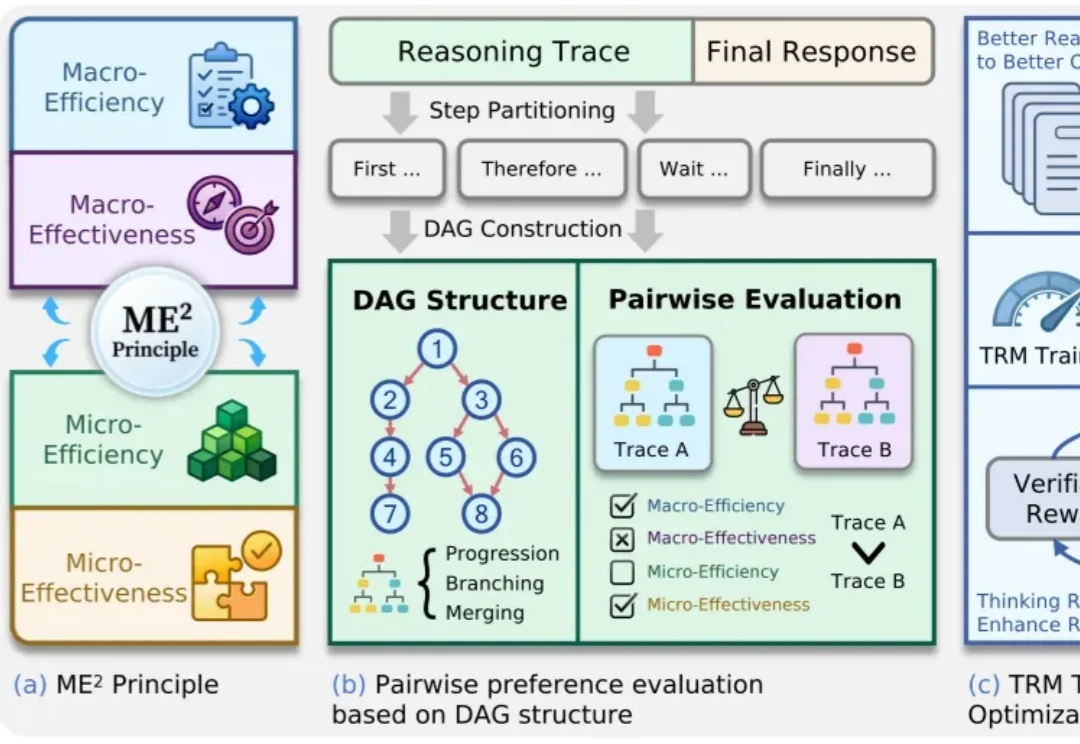
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
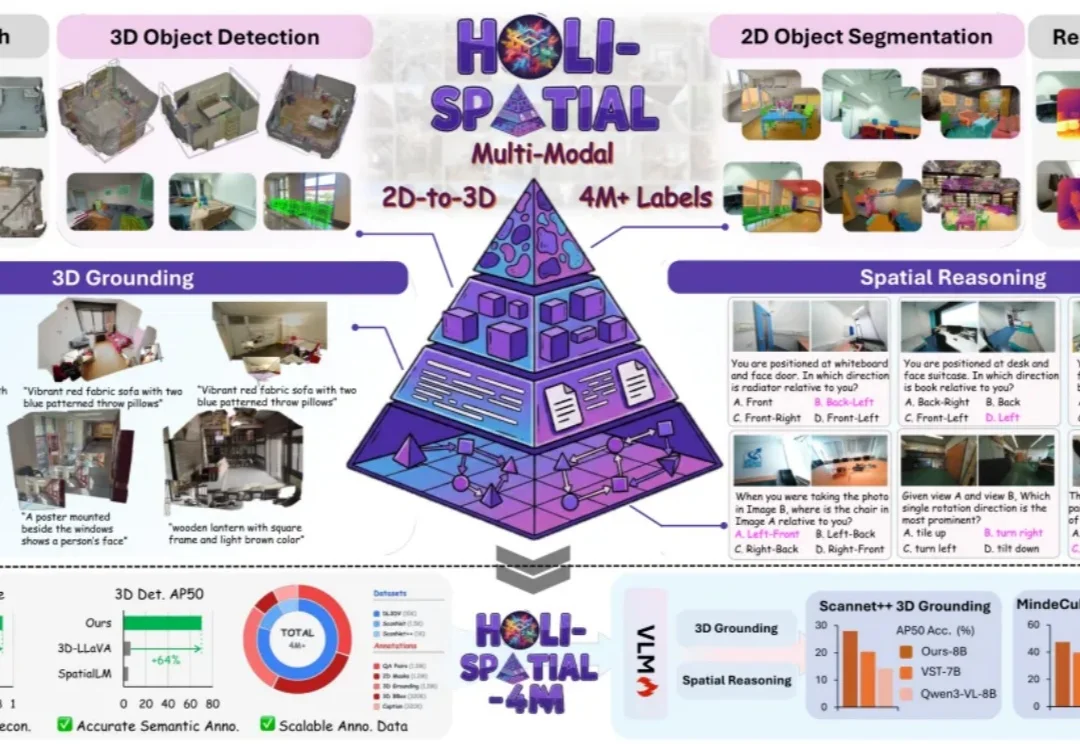
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
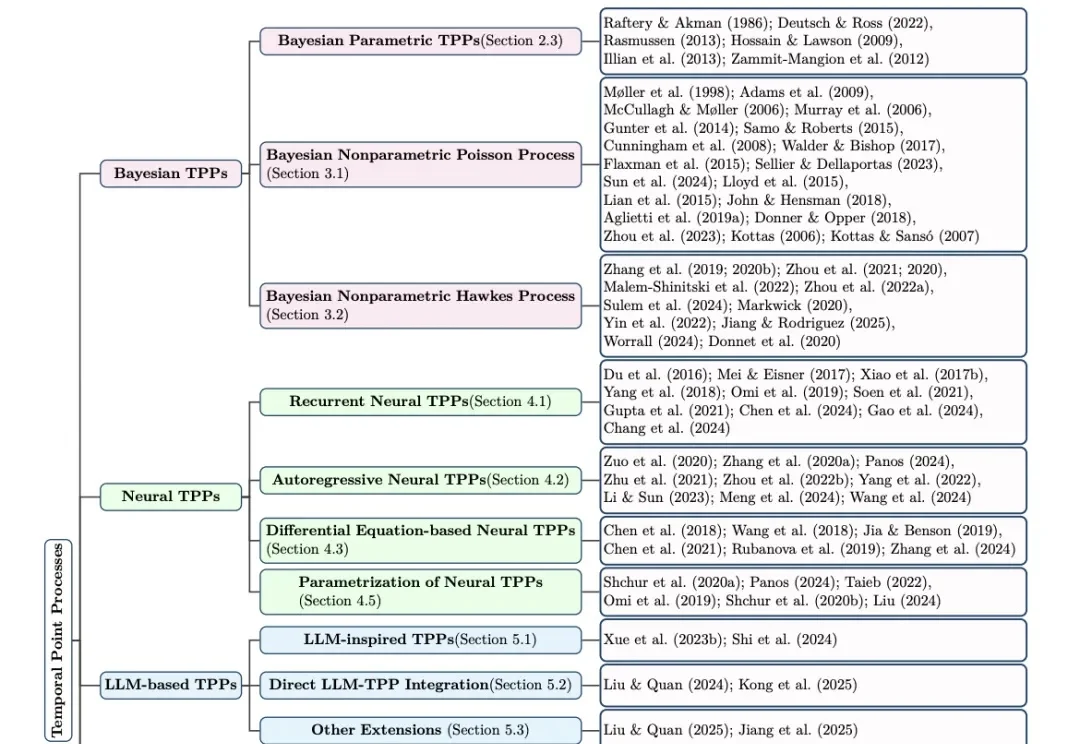
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?
Coralogix,一家总部位于波士顿、创立于以色列的软件监控初创公司,已在新一轮融资中筹集 2 亿美元。该投资押注 AI Agent 的兴起将催生新一代工具的需求,用于监控、排障并管理日益自主化的软件系统。
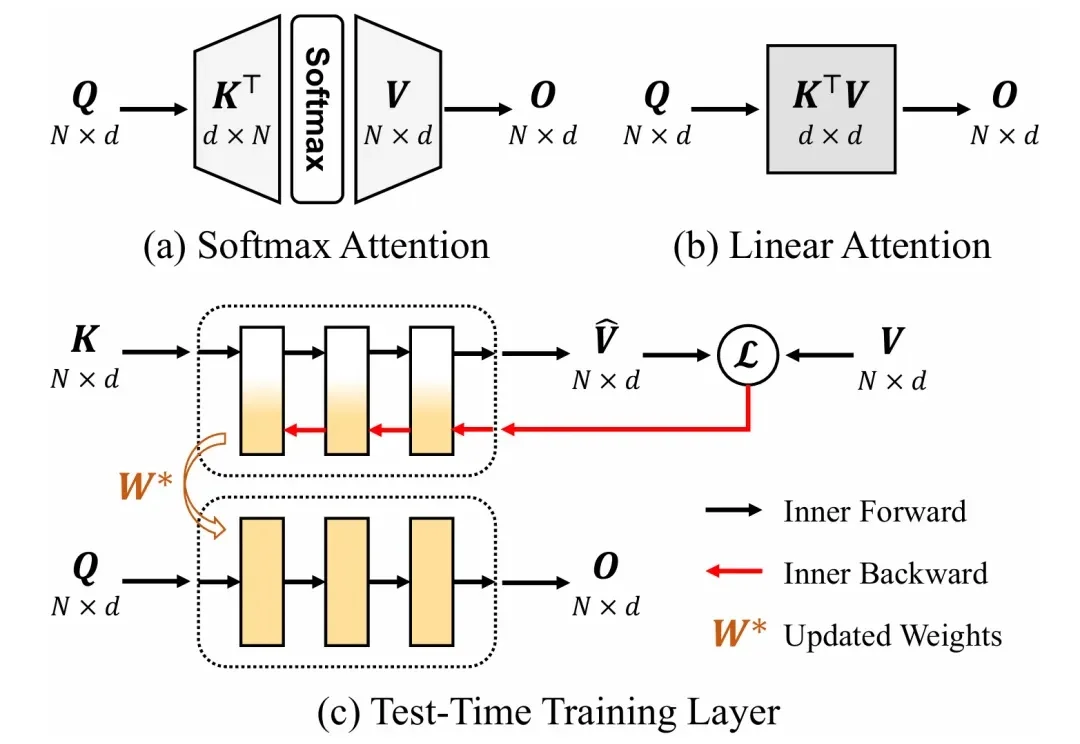
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
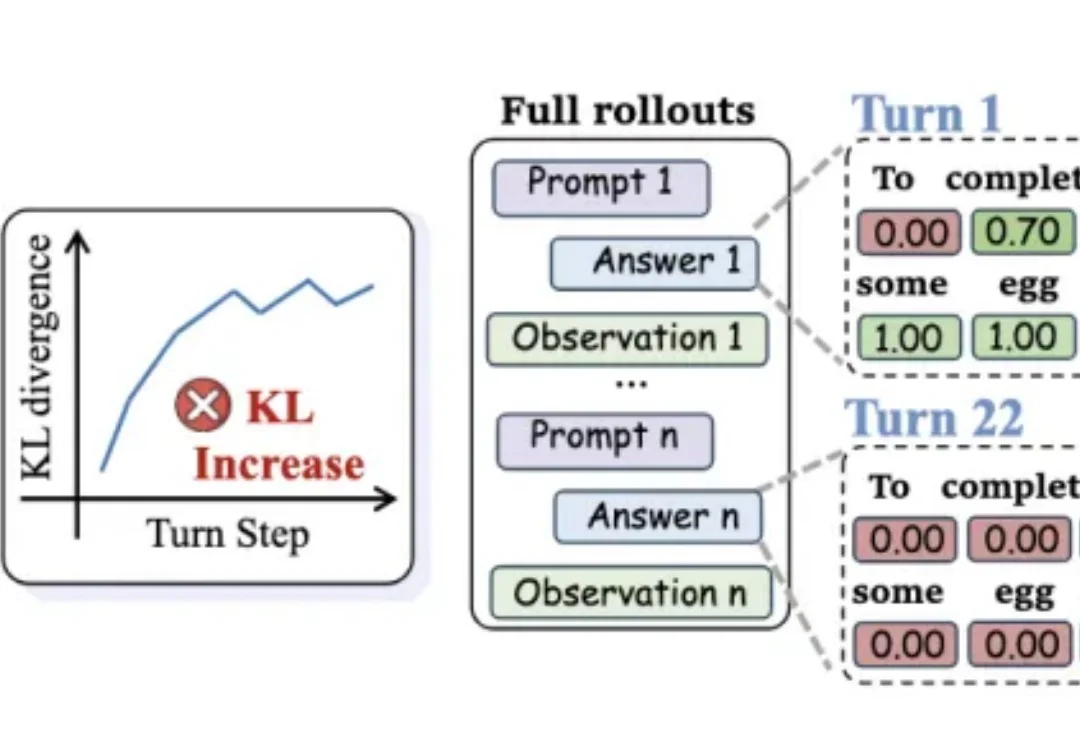
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。