独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?
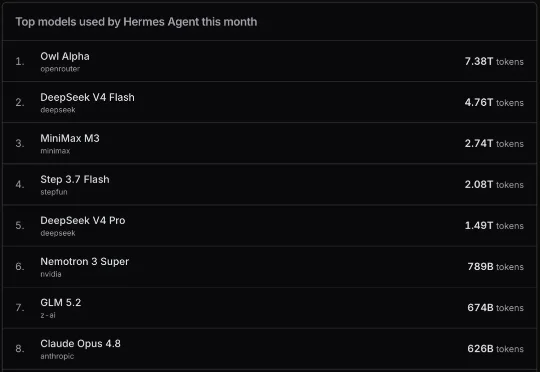
独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。
来自主题: AI资讯
8014 点击 2026-07-02 21:36
 搜索
搜索
最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。

今天来聊聊中转站。
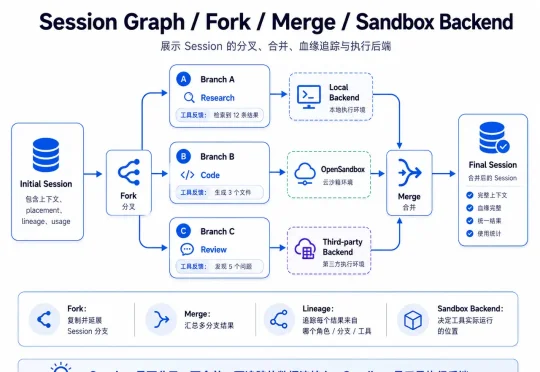
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。
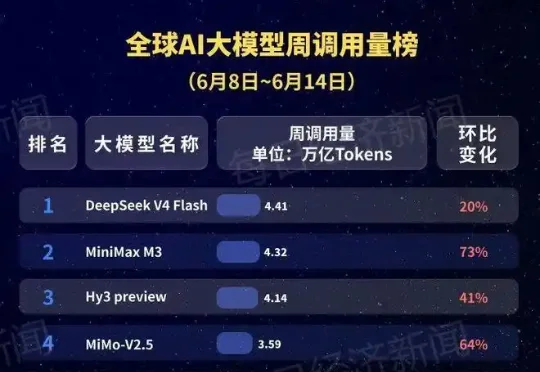
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。
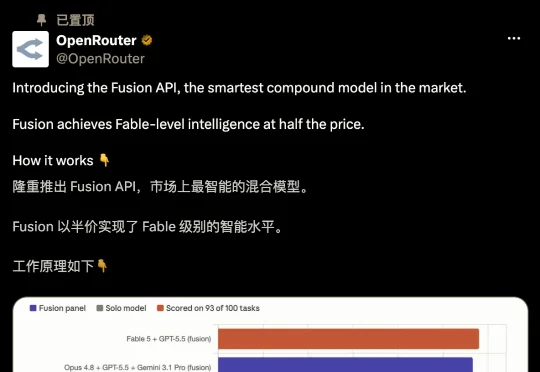
OpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。

昨晚,AI模型聚合平台OpenRouter宣布完成1.13亿美元(约合人民币7.67亿元)的B轮融资。本轮融资由谷歌母公司Alphabet旗下的成长基金CapitalG领投,英伟达NVentures、ServiceNow等一众风险投资机构跟投,a16z、Menlo Ventures持续加注。外媒报道,该公司融资过后估值飙升至13亿美元(约合人民币88.22亿元)。

每周25万亿tokens的真实流量、估值一年翻倍——OpenRouter拿下1.13亿美元B轮融资。

最近,DeepSeek又刷屏了!

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :