手把手带你入门机器人学习,HuggingFace联合牛津大学新教程开源SOTA资源库
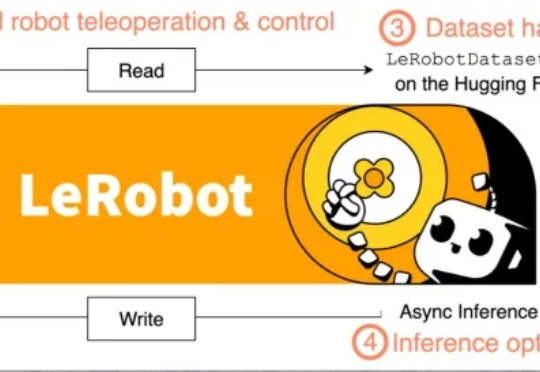
手把手带你入门机器人学习,HuggingFace联合牛津大学新教程开源SOTA资源库HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。
来自主题: AI技术研报
10553 点击 2025-10-26 16:28