我的王者荣耀有救了!谷歌发布游戏SIMA 2,不开外挂「像人一样」练级
我的王者荣耀有救了!谷歌发布游戏SIMA 2,不开外挂「像人一样」练级如果一个AI,像人类一样看屏幕、敲键鼠、自己练级变强,这种游戏搭子,你愿意拥有吗?可能不久将来,类似王者荣耀、DOTA 2这样的游戏就可以选择和AI组队,而不是和人组队了!
来自主题: AI资讯
9788 点击 2025-11-14 14:30
 搜索
搜索
如果一个AI,像人类一样看屏幕、敲键鼠、自己练级变强,这种游戏搭子,你愿意拥有吗?可能不久将来,类似王者荣耀、DOTA 2这样的游戏就可以选择和AI组队,而不是和人组队了!
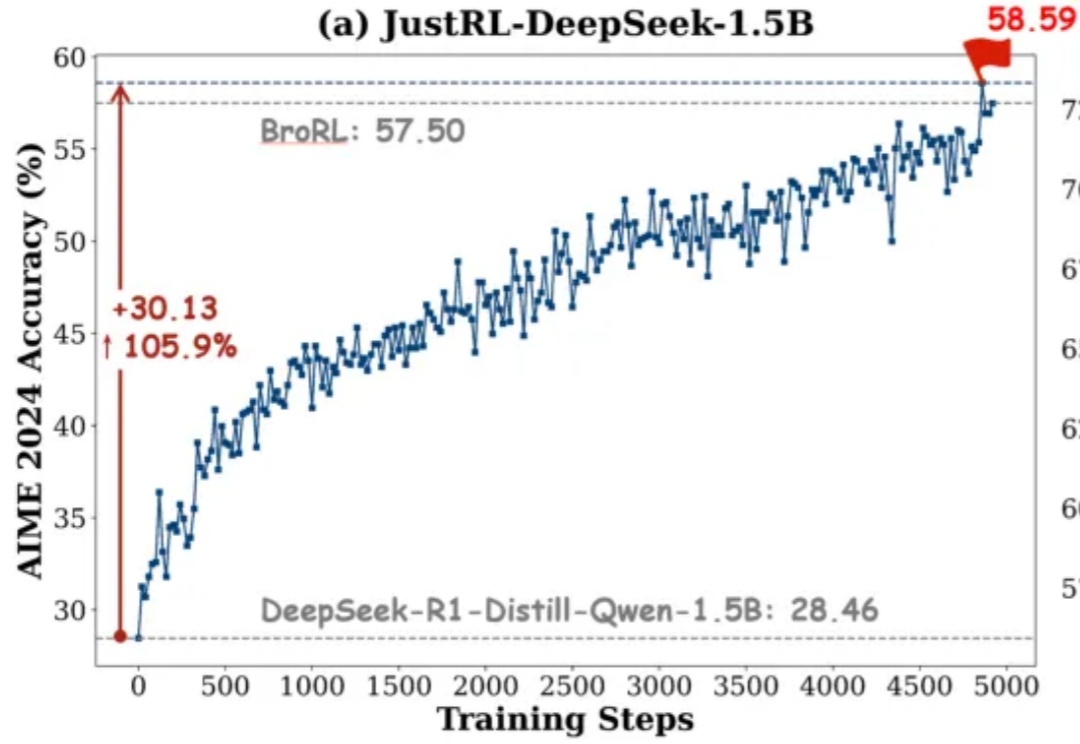
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?
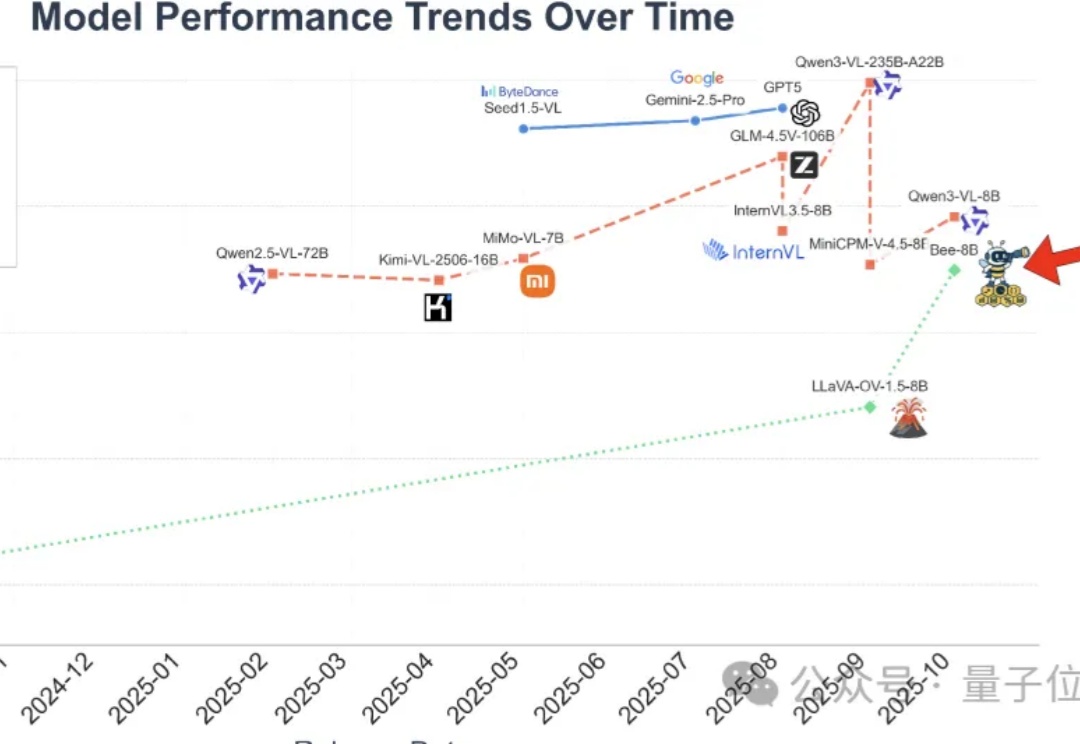
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。

这周一,一张神秘海报在科技圈引发热议。
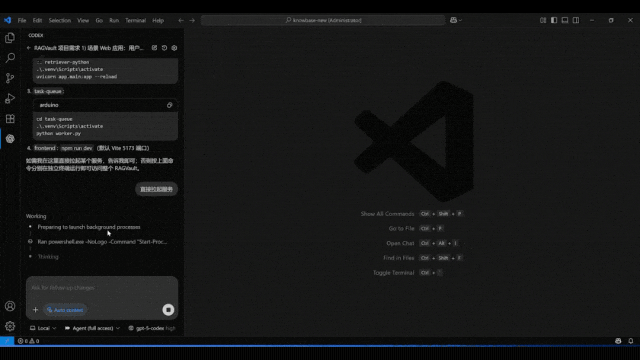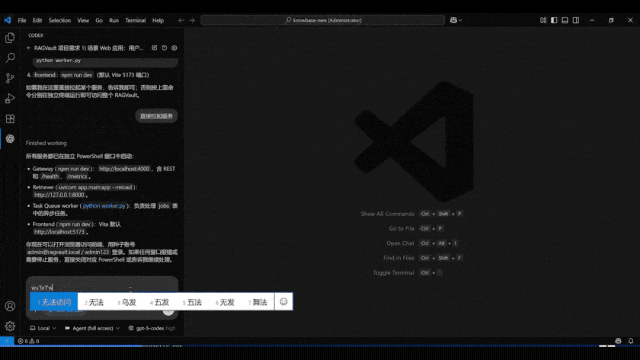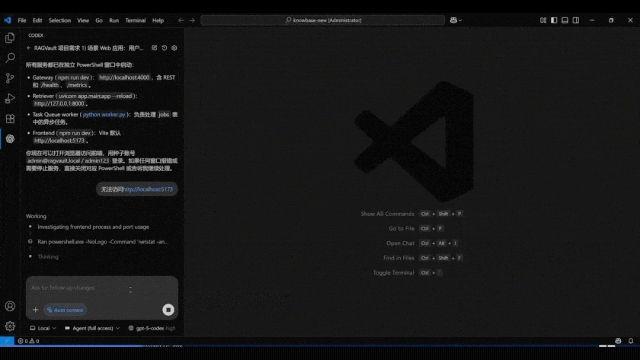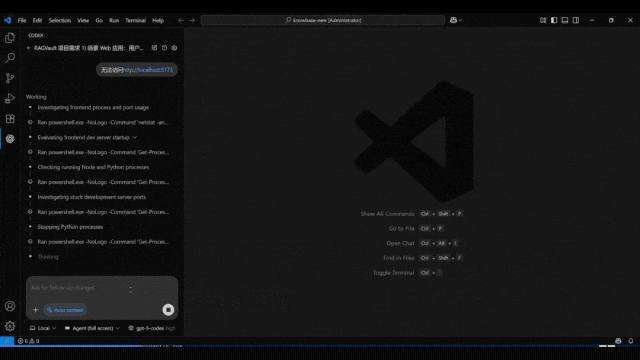
这一次带来如此新SOTA效果的,是全球首个实现项目级开发的AI IDE——Vinsoo。刚刚,Vinsoo上新Beta 3.0版本,仅用国产大模型(Qwen),就超越了搭载Claude的Cursor、Codex、Claude Code等一众流行AI编程产品。Vinsoo是芸思智能推出的全球首个搭载云端安全Agent编程团队的AI IDE,主打从需求确认到交付验收,AI全流程自动推进项目开发。

比Nano Banana更擅长P细节的图像编辑模型来了,还是更懂中文的那种。

最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
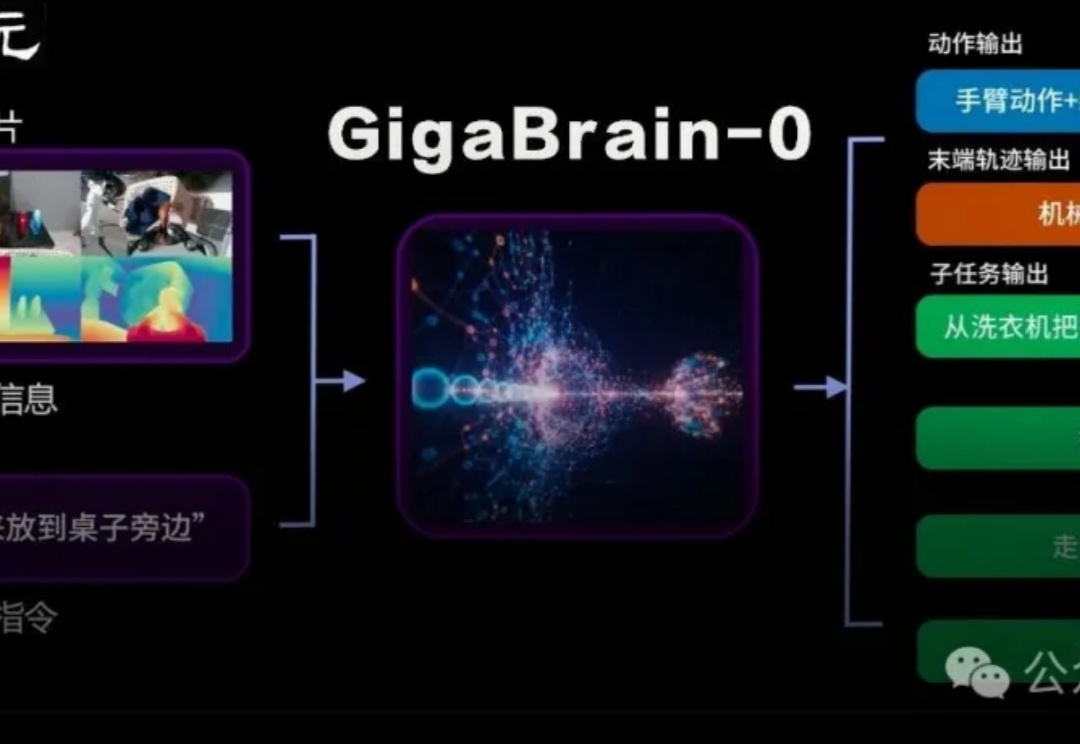
国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。

3D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。
美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。