
刚刚,万元级个人机器人再升级!喊一声就跳英歌舞
刚刚,万元级个人机器人再升级!喊一声就跳英歌舞小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。
来自主题: AI资讯
8206 点击 2026-06-30 10:47
 搜索
搜索
小布米OTA V3.0来了。喊一声就跳舞,拖拽胳膊就学会新动作,还能跟你打拳——你的第一个个人机器人,这次真的听话了。
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。

一觉醒来,AI的新潮流变成了养猫???火速围观一下,刚刚全球流式音视频模型赛道闯进了一匹黑马,能力SOTA级,模型名字就叫缅因猫(MaineCoon)。养过缅因猫的朋友都知道,这个品种有个外号叫「猫狗」,意思是几乎你走到哪儿,它就跟到哪儿,相当粘人,互动感MAX。
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。

一颗土豆,表皮上爬满发光电路,焦黄的皮和银色走线贴在一起,像是英伟达和肯德基联名了。 标题端端正正:Potato Chip Tech Summit——一颗土豆如何颠覆半导体行业。 这是我们给 AI 出
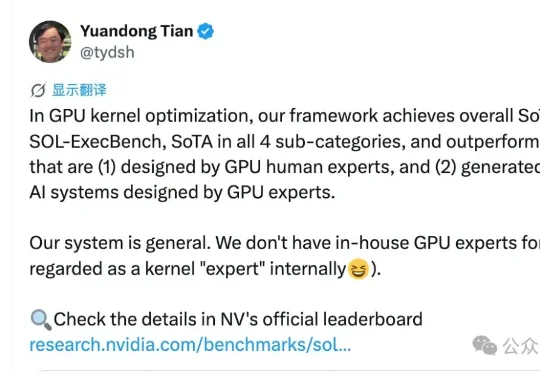
刚刚,田渊栋创业公司,交出了首个研究成果。田渊栋在X上宣布,其创立的Recursive,在NVIDIA官方的GPU kernel优化榜SOL-ExecBench上拿下了整体和四个子类别的SOTA。
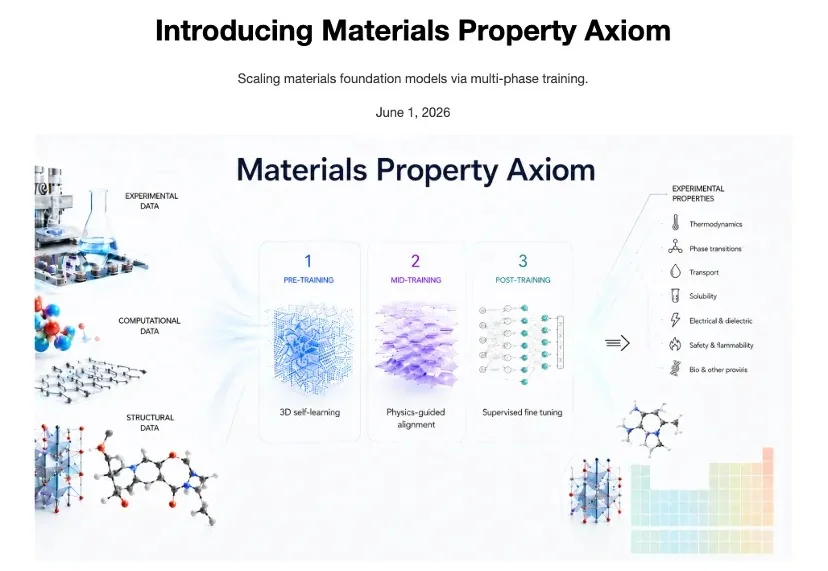
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。