
19岁少年「破解」谷歌新AI?每秒1479 token,扩散再战GPT!
19岁少年「破解」谷歌新AI?每秒1479 token,扩散再战GPT!年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。
来自主题: AI资讯
9755 点击 2025-05-24 19:28
 搜索
搜索
年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。
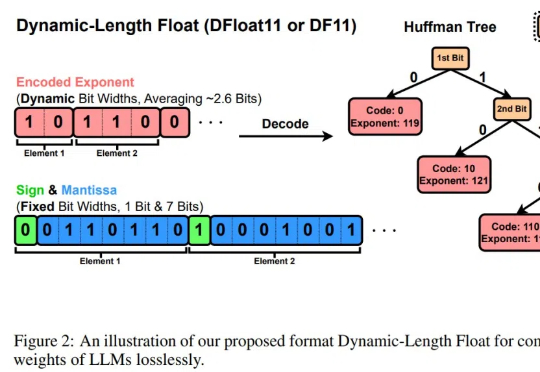
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。

关注NLP领域的人们,一定好奇「语言模型能做什么?」「什么是o1?」「为什么思维链有效?」
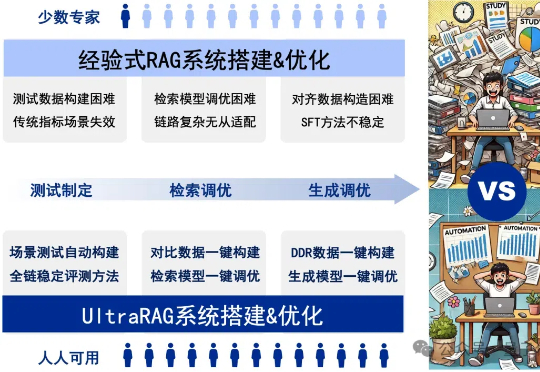
RAG系统的搭建与优化是一项庞大且复杂的系统工程,通常需要兼顾测试制定、检索调优、模型调优等关键环节,繁琐的工作流程往往让人无从下手。
DeepMind近两万引科学家Felix Hill,去世了。 他参与过NLP领域经典的GLUE和SuperGLUE基准,2016年起在DeepMind工作直到最后一天。
评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。
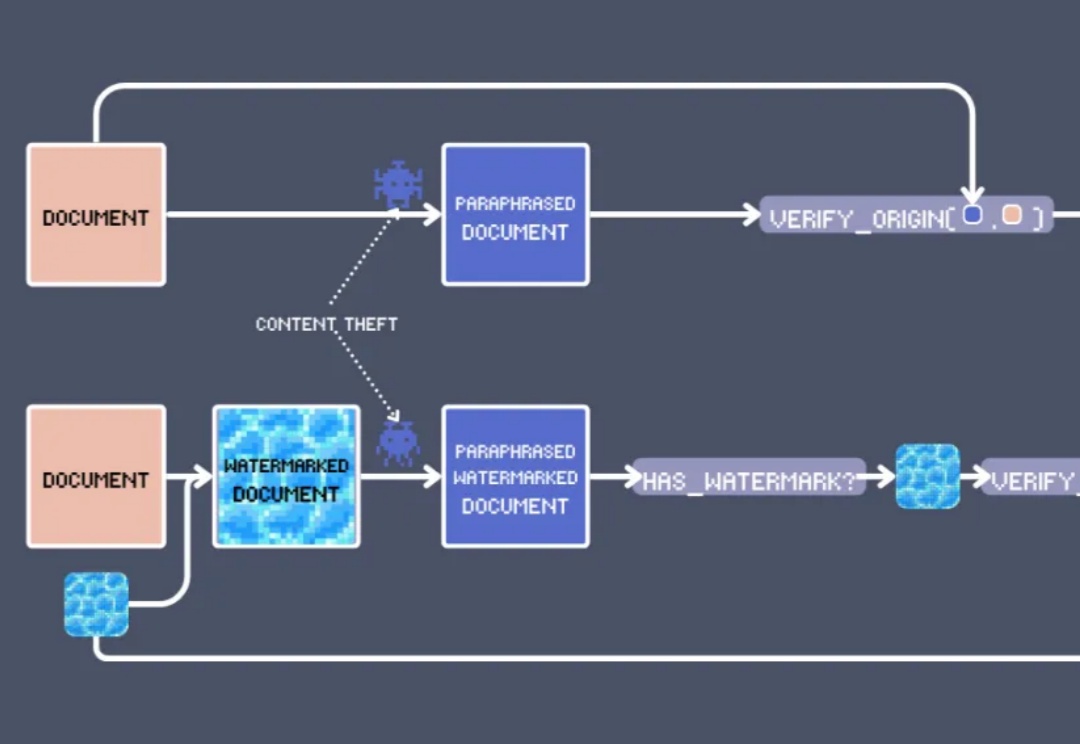
在 EMNLP 2024 上,我们看到了向量模型的各种创新用法,其中最出人意料的莫过于:文本水印。

作为自然语言处理(NLP)领域的顶级盛会,EMNLP 每年都成为全球研究者的关注焦点。

清华大学NLP实验室联合北京师范大学、中国科学院大学、东北大学等机构的研究人员推出了全新的评测方法 RAGEval,通过快速构建场景化评估数据实现对检索增强生成(RAG)系统的“精准诊断”。

让大模型能快速、准确、高效地吸收新知识!