拆解Gemini 3:Scaling Law的极致执行与“全模态”的威力
拆解Gemini 3:Scaling Law的极致执行与“全模态”的威力毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。
来自主题: AI资讯
10173 点击 2025-11-24 15:26
 搜索
搜索
毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。

今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
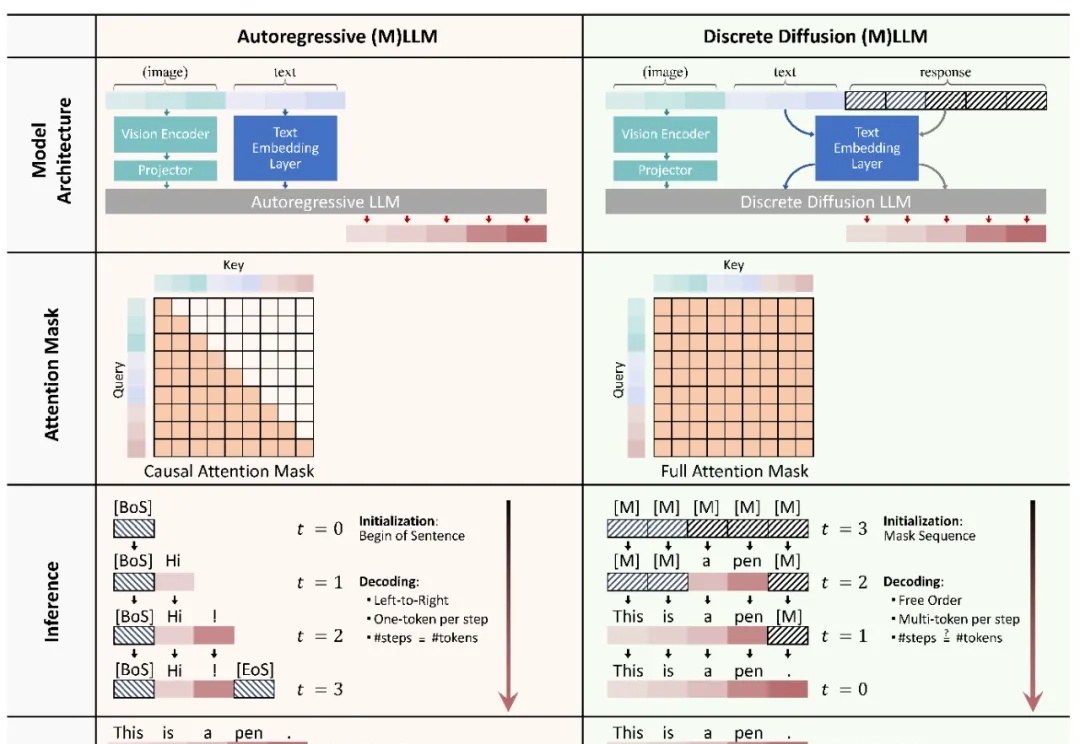
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
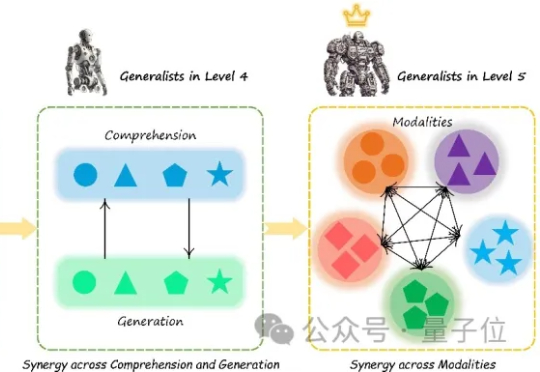
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
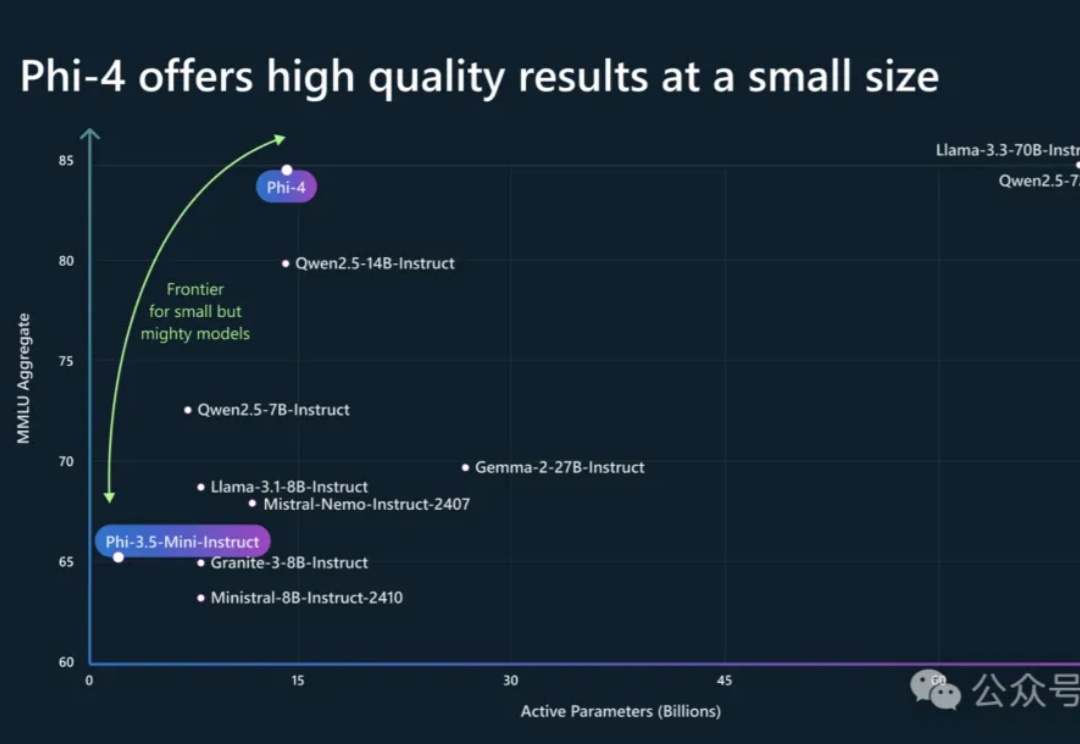
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。