
MuleRun Messages上线!Agent从个人工具走进团队协作
MuleRun Messages上线!Agent从个人工具走进团队协作今天,MuleRun正式上线Messages。作为MuleRun Enterprise版的AI协作IM,Messages的核心设计是让人类员工与AI Agent在同一个工作空间里像同事一样协作——Agent可以被@、可以被拉群、可以持续参与工作流程。
来自主题: AI资讯
9039 点击 2026-06-02 21:24
 搜索
搜索
今天,MuleRun正式上线Messages。作为MuleRun Enterprise版的AI协作IM,Messages的核心设计是让人类员工与AI Agent在同一个工作空间里像同事一样协作——Agent可以被@、可以被拉群、可以持续参与工作流程。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。
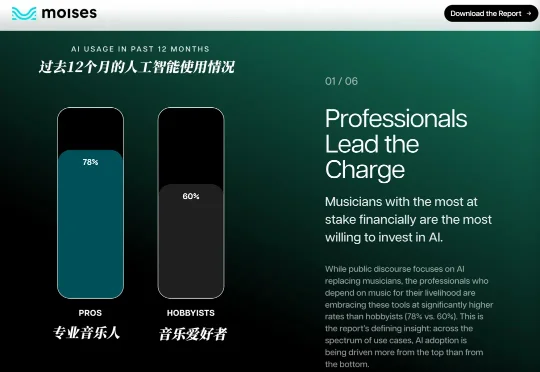
音乐产业正在经历一个新的“奥德赛时期”,变量无疑来自AI。到目前为止,专业音乐人们大都对使用AI讳莫如深,但一些报告称,AI已经在行业里广为普及。今年3月,moises和Water & Music联合发布的报告称,专业音乐人的AI使用率达到78%。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

前几天大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。

具身智能(Embodied AI)正在快速从实验室走向真实世界。

旧金山开发者Affaan Mustafa把Claude Code打磨成38个专业智能体、156项技能的超级系统,开源后短短时间冲上GitHub 15万星!
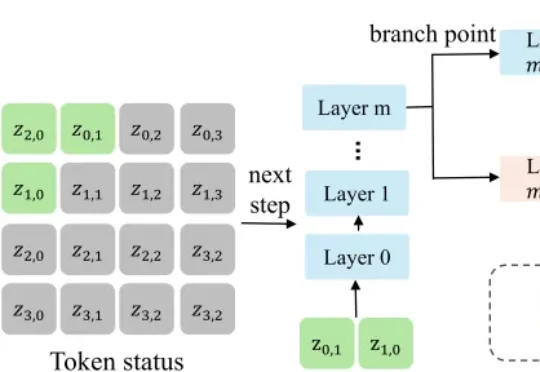
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

老黄在北京喝豆汁「翻车」,全网笑疯了。但真正值得警惕的,是他背后那个正在长出来的「中国版CUDA生态」。从万卡集群到机器狗,从SGLang主线到AI Agent自动迁移,这家公司这次不只是秀芯片,而是在重写国产GPU的游戏规则!
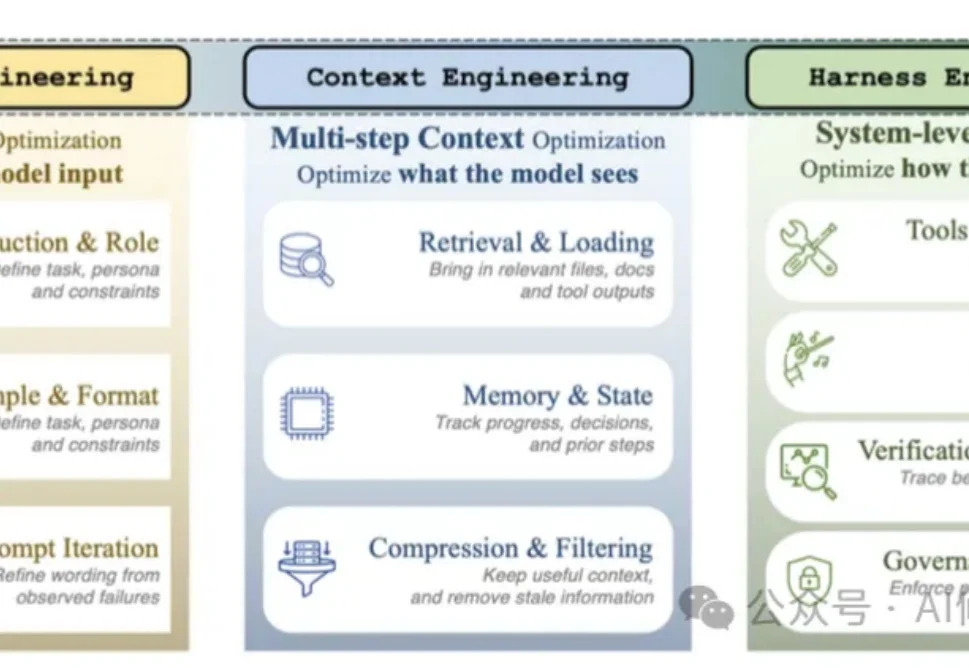
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。