
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛
Hermes上线MoA功能!比Opus 4.8和GPT-5.5还猛近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。
来自主题: AI资讯
9012 点击 2026-07-01 00:22
 搜索
搜索
近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。
今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:
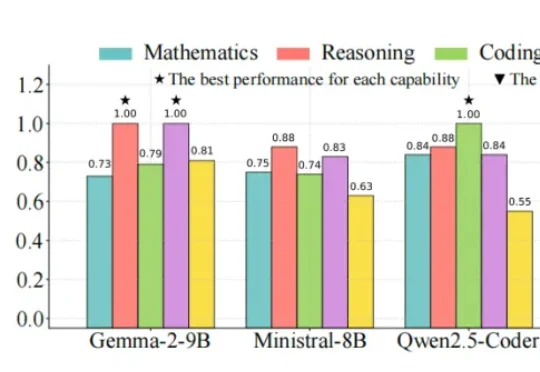
研究者开始尝试让 MoA 变稀疏。例如,一些方法如 Sparse MoA 会先让模型池中的所有模型生成回答,再通过额外的评审模型进行打分和筛选,只保留一部分模型进入后续协作。这样虽然减少了后续融合的负担,但本质上仍然绕不开一个问题:为了决定该选谁,系统还是得先让所有模型都推理一遍。
如果你正在开发Agent产品,一定听过或用过Mixture-of-Agents(MoA)架构。这个让多个AI模型协作解决复杂问题的框架,理论上能够集众家之长,实际使用中却让人又爱又恨:

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

文字、图片、视频,万物皆可动漫化!

视频的次元壁就这么被打破了。在 AI 的加持下,一张照片可以千变万化,其实视频也能。