
扎克伯格承认:Meta AI智能体研发不及预期
扎克伯格承认:Meta AI智能体研发不及预期今日,据路透社报道,Meta创始人兼CEO马克·扎克伯格(Mark Zuckerberg)当地时间7月2日在公司内部全员会上承认,过去至少四个月,AI智能体技术的研发进展并未如他预期般提速,Meta押注AI新组织架构的布局“至今尚未落地见效”。路透社称,这一信息来自其听取的一段会议录音。
来自主题: AI资讯
7213 点击 2026-07-03 16:11
 搜索
搜索
今日,据路透社报道,Meta创始人兼CEO马克·扎克伯格(Mark Zuckerberg)当地时间7月2日在公司内部全员会上承认,过去至少四个月,AI智能体技术的研发进展并未如他预期般提速,Meta押注AI新组织架构的布局“至今尚未落地见效”。路透社称,这一信息来自其听取的一段会议录音。

OpenAI首席研究官Mark Chen释放了一个强烈信号:OpenAI 并不认为scaling laws已经失效,恰恰相反,预训练、数据工程、推理训练和更长任务链条,仍是通向AGI的主干道路。
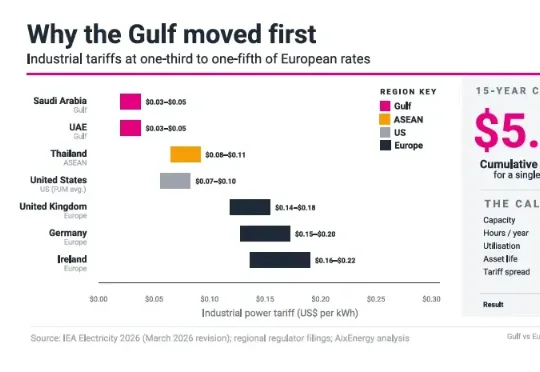
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。

我们最近在重新思考一件事:到底什么样的 Benchmark,才值得今天继续做?

从v0.7开始,我先给 Humanize PPT 划了一条边界。把渲染PPT页面外包给下游的Skill。Humanize PPT负责把大纲,逐页意图,视频和图片素材的坑位和演讲稿,整理成结构化的 JSON 与 Markdown,再交给下游 Skill 原生渲染。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

今年开年以来,不管是硅谷、还是国内的 AI 投资圈子,都不太敢投 AI 应用了。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。
之前预告过的那个「手机上的 Markdown / HTML 阅读器」做完了,叫 即览。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,