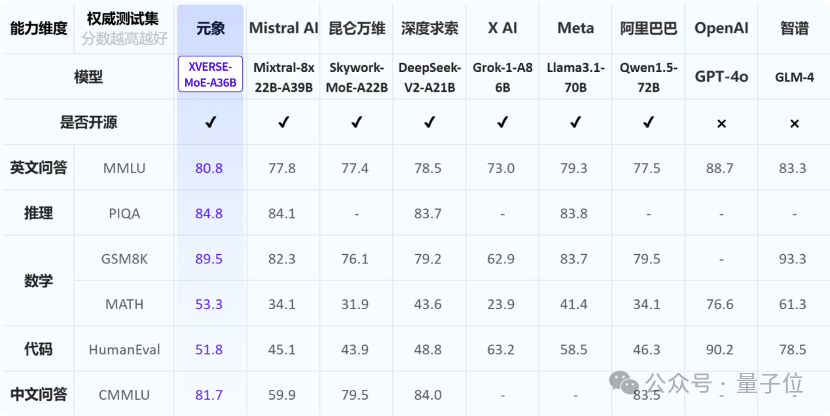
中国最大开源MoE模型,255B参数无条件免费商用,元象发布
中国最大开源MoE模型,255B参数无条件免费商用,元象发布元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。
来自主题: AI资讯
6206 点击 2024-09-14 14:58
 搜索
搜索
元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。
微软Phi 3.5系列上新了!mini模型小而更美,MoE模型首次亮相,vision模型专注多模态。

前几天,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,论文提出构建完全可微的MoE模型,是一种预训练自回归语言模型的新方法。

开源大模型领域,又迎来一位强有力的竞争者。

就在刚刚,拥有128位专家和4800亿参数的Arctic,成功登上了迄今最大开源MoE模型的宝座。
Snowflake 发布高「企业智能」模型 Arctic,专注于企业内部应用。
一条磁力链,Mistral AI又来闷声不响搞事情。
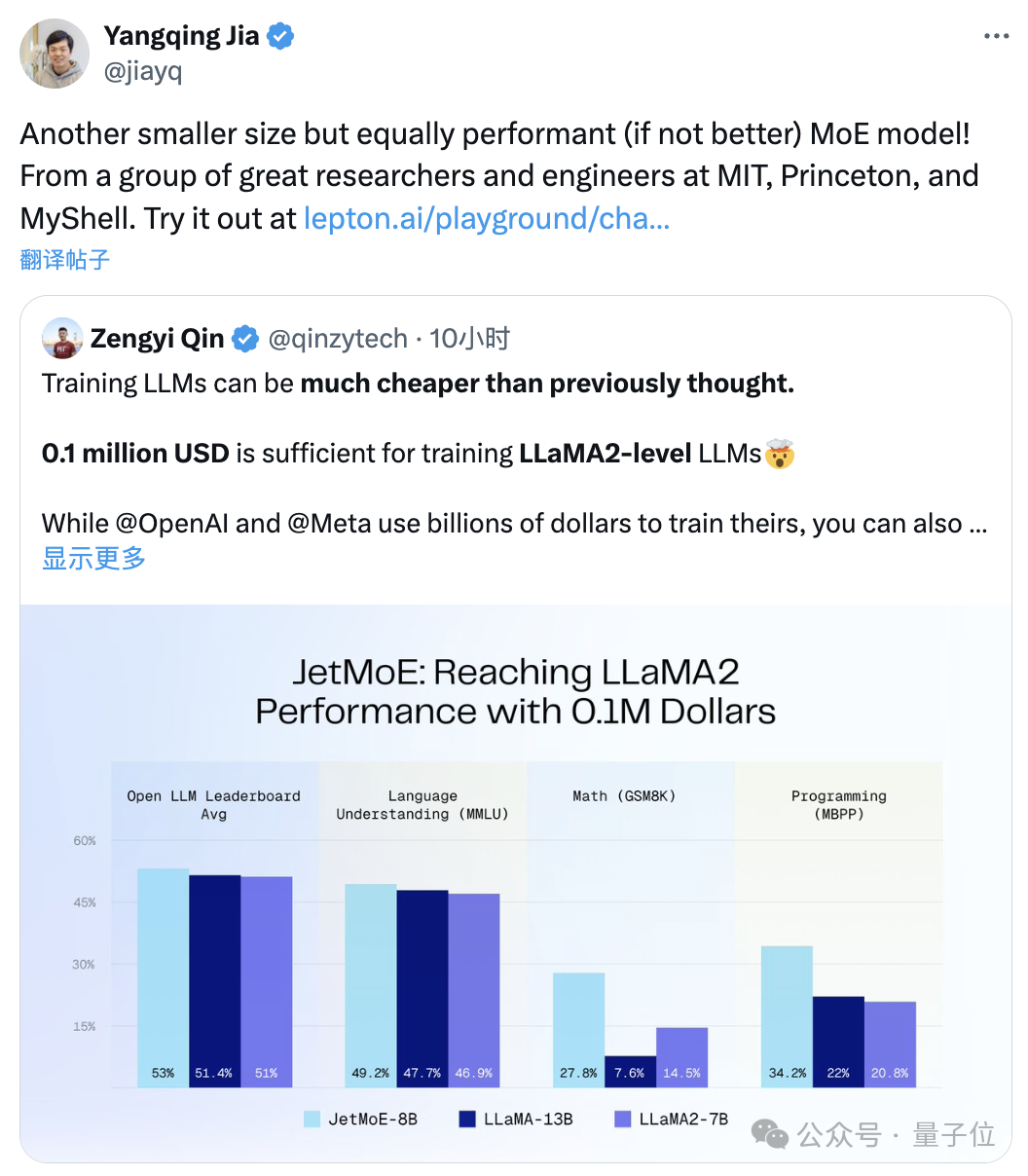
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。

一年一度的CVPR 2024录用结果出炉了。今年,共有2719篇论文被接收,录用率为23.6%。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。