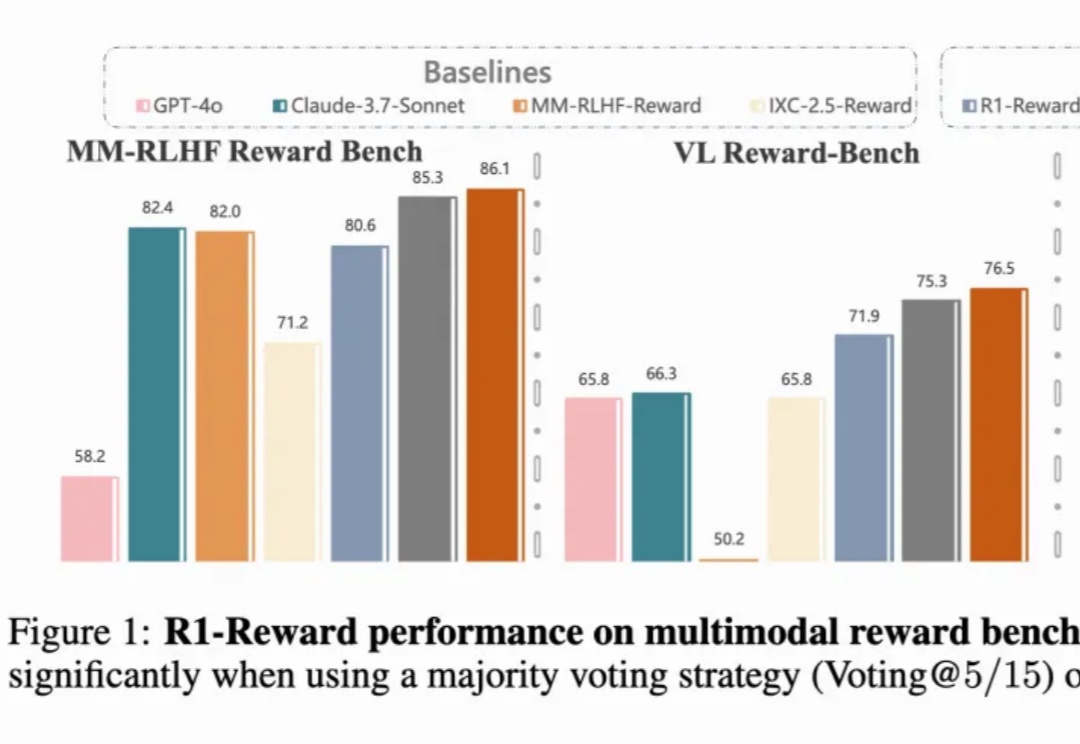
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
来自主题: AI技术研报
10141 点击 2025-05-09 11:51
 搜索
搜索
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
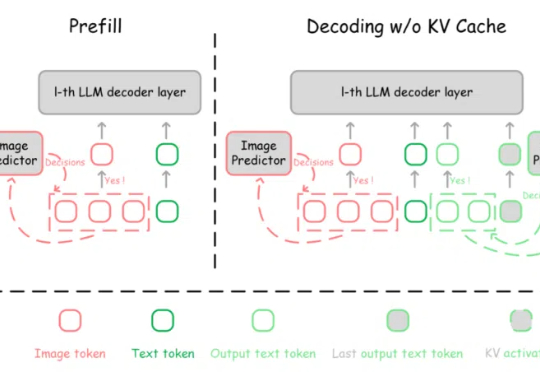
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
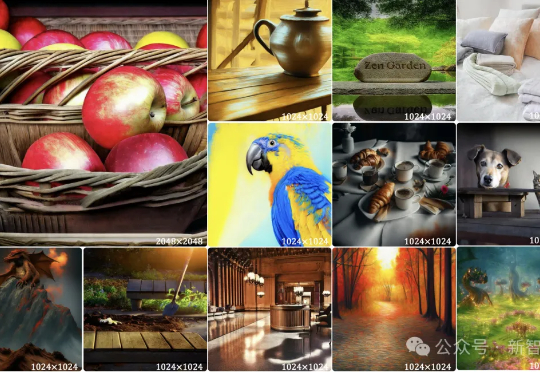
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

阶跃星辰正式发布并开源图像编辑大模型 Step1X-Edit,性能达到开源 SOTA。该模型总参数量为 19B (7B MLLM + 12B DiT),具备语义精准解析、身份一致性保持、高精度区域级控制三项关键能力;支持 11 类高频图像编辑任务类型,如文字替换、风格迁移、材质变换、人物修图等。
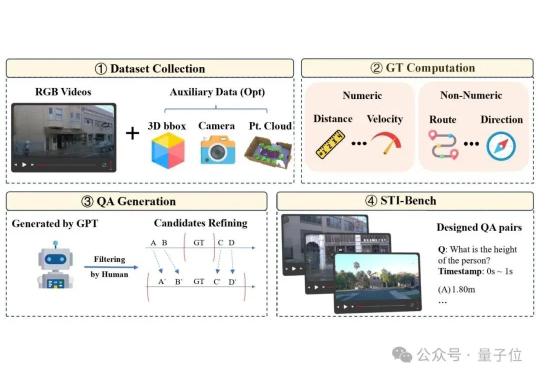
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。