邢波再出手:上次「骂」完世界模型,这次轮到智能体了
邢波再出手:上次「骂」完世界模型,这次轮到智能体了去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
来自主题: AI技术研报
6742 点击 2026-07-01 15:43
 搜索
搜索
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。
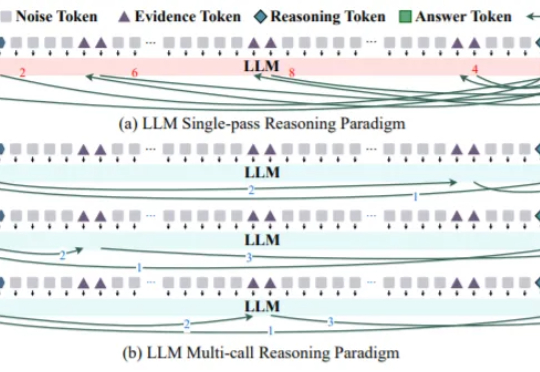
近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。
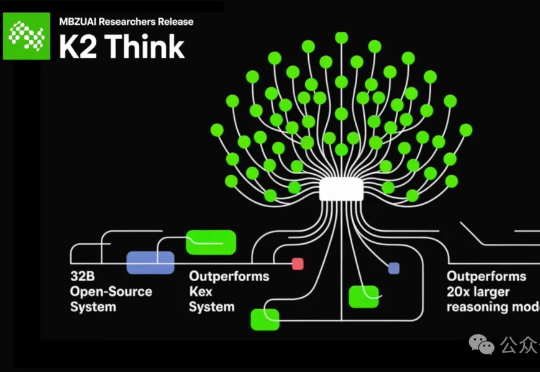
全球最快的开源大模型来了——速度达到了每秒2000个tokens! 虽然只有320亿参数(32B),吞吐量却是超过典型GPU部署的10倍以上的那种。它就是由阿联酋的穆罕默德·本·扎耶德人工智能大学(MBZUAI)和初创公司G42 AI合作推出的K2 Think。

在阿联酋 2031 国家人工智能战略的驱动下,穆罕默德・本・扎耶德人工智能大学(MBZUAI) 正以 AI 专业学术全球排名前十的硬实力,重塑 AI 教育格局。这所由阿联酋总统创立的学术引擎,不仅承载着中东向科技转型的雄心,更以丰厚奖学金覆盖所有学位项目,为全球优秀人才铺就一条通往未来的黄金大道。

Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。
全世界第一所人工智能大学 MBZUAI 全球招贤纳才。

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。