
视频扩散模型新突破!清华腾讯联合实现高保真3D生成,告别多视图依赖
视频扩散模型新突破!清华腾讯联合实现高保真3D生成,告别多视图依赖三维场景是构建世界模型、具身智能等前沿科技的关键环节之一。
来自主题: AI技术研报
8429 点击 2025-06-14 12:43
 搜索
搜索
三维场景是构建世界模型、具身智能等前沿科技的关键环节之一。
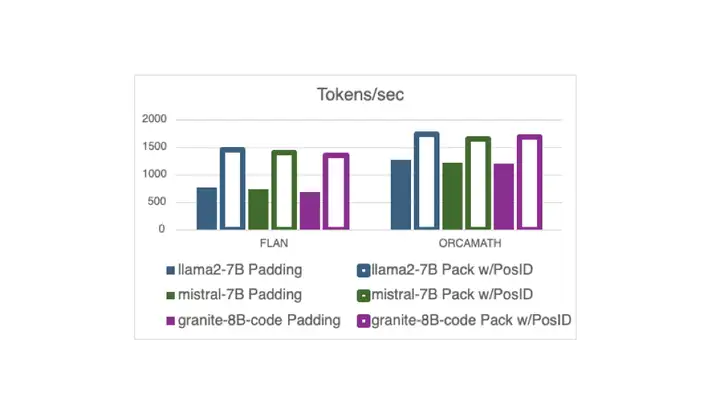
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!

随着 Sora 的成功发布,视频 DiT 模型得到了大量的关注和讨论。设计稳定的超大规模神经网络一直是视觉生成领域的研究重点。DiT [1] 的成功为图像生成的规模化提供了可能性。