
一次三篇!李飞飞的空间智能公司,发论文了
一次三篇!李飞飞的空间智能公司,发论文了今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。
来自主题: AI资讯
10959 点击 2026-06-13 14:36
 搜索
搜索
今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。
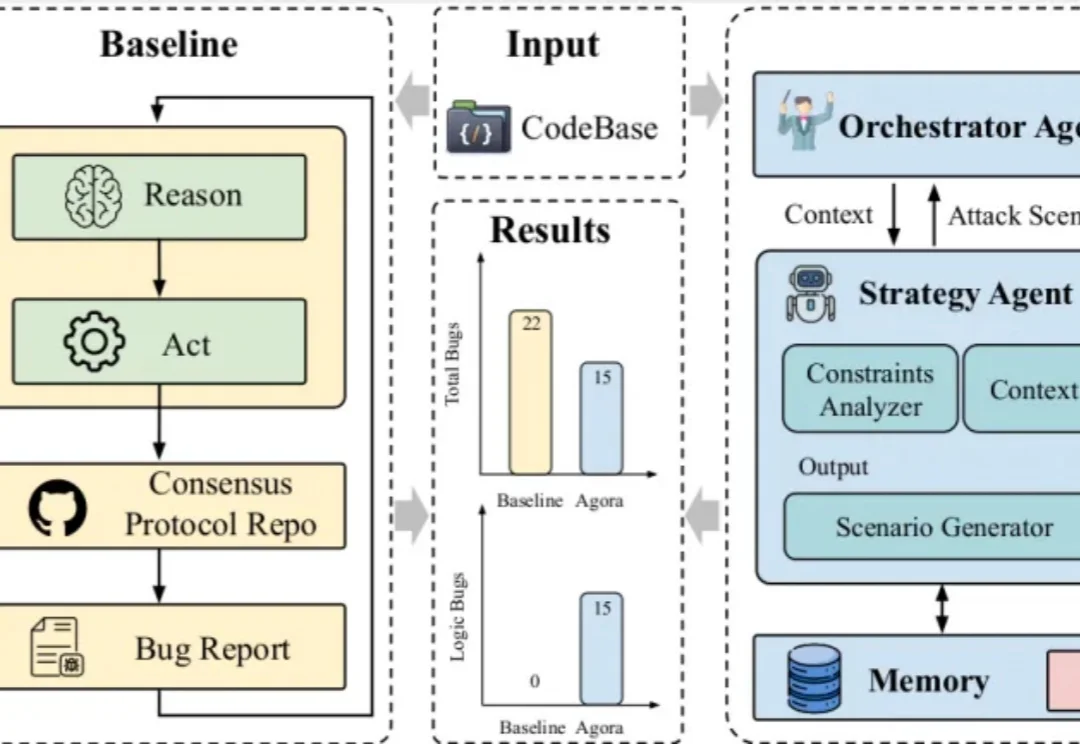
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。

世界模型第一次塞进指甲盖芯片!X-Era Lab与星宸科技联手,成本砍掉90%,具身智能终于不靠云端活了。

在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务

它不同于我们认知中传统的「学术机构」or「创业公司」。它要在同一个屋顶下,同时扛住四件事:科学路径是否成立、工程能不能跑通、市场有没有人买单、资本能不能撑到关键节点。硅谷现在有个非正式叫法:Neo Labs。

在人工智能与体育产业深度融合的浪潮中,高尔夫这项传统运动正迎来一场由“物理AI”驱动的技术革命。近日,专注于高尔夫运动科技创新的XintLabs宣布完成数千万元天使轮融资,由高瓴创投独家投资。资金将主