CVPR 2026 | 从视觉Token内在变化量出发,实现VLM无损加速1.87倍
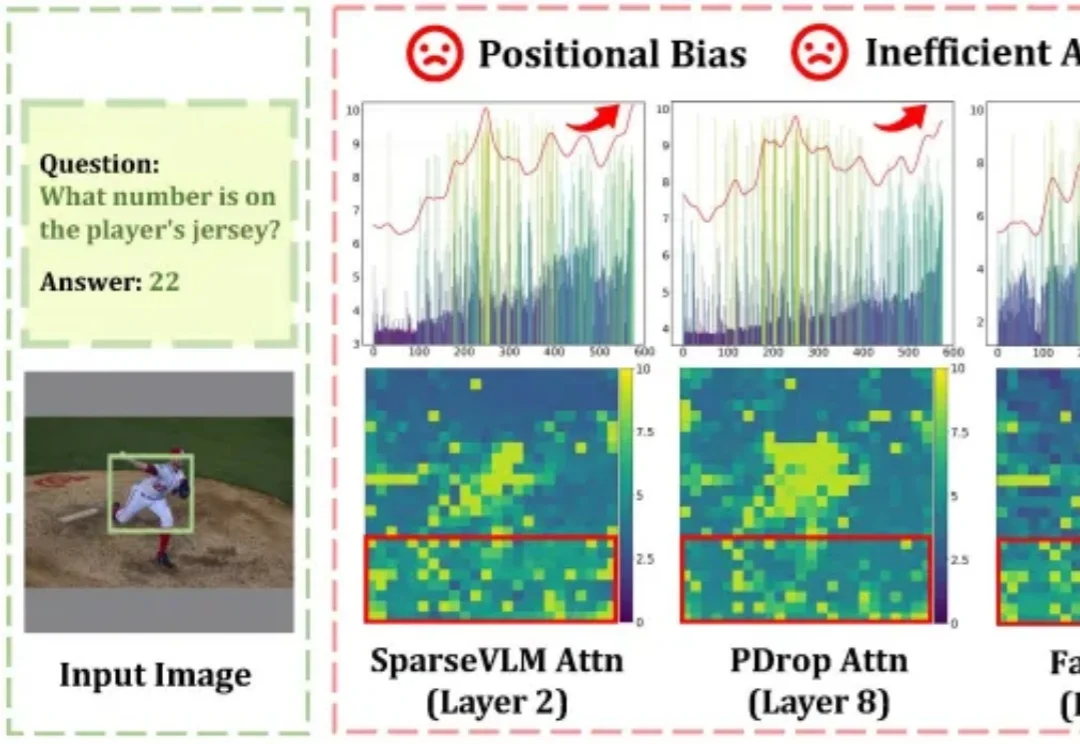
CVPR 2026 | 从视觉Token内在变化量出发,实现VLM无损加速1.87倍随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
来自主题: AI技术研报
9495 点击 2026-03-17 08:49