R-HORIZON:长程推理时代来临,复旦NLP&美团LongCat重磅发布LRMs能力边界探测新范式
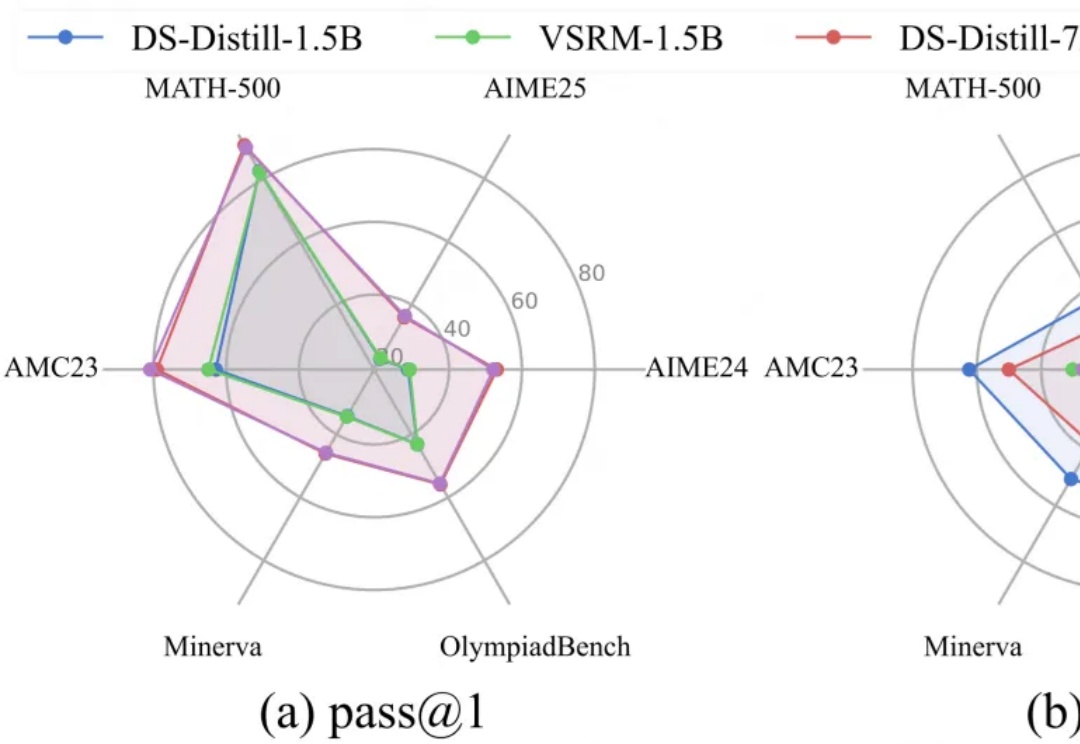
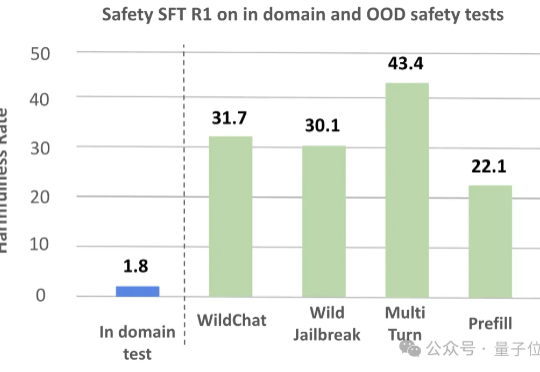
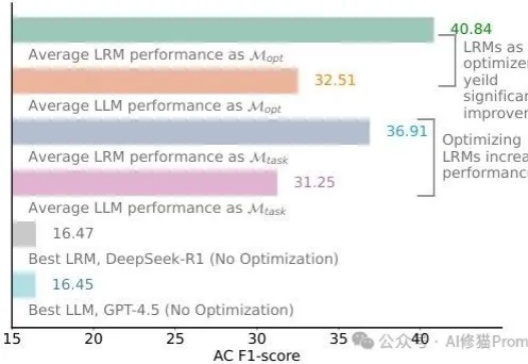
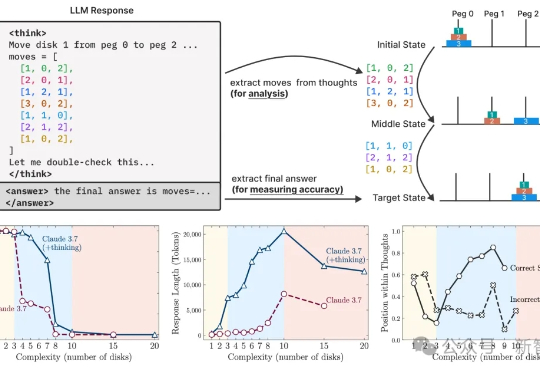
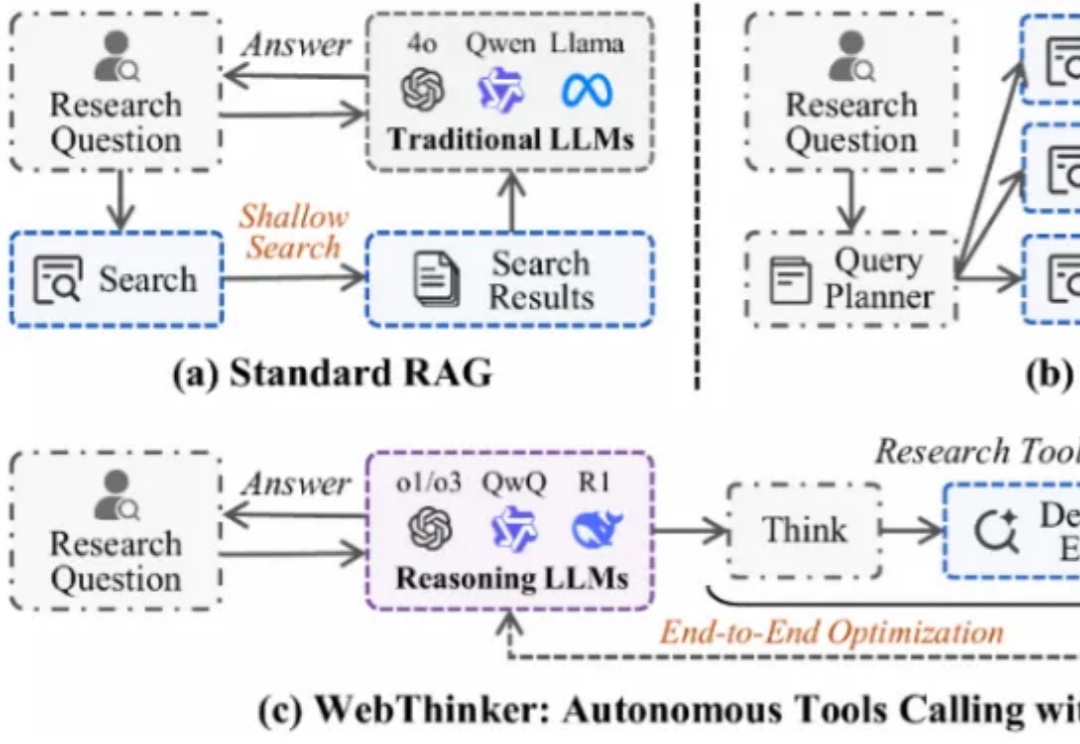
R-HORIZON:长程推理时代来临,复旦NLP&美团LongCat重磅发布LRMs能力边界探测新范式当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。
来自主题: AI技术研报
8407 点击 2025-10-23 16:22