你的怀疑是对的!LLM作为Judge,既无效又不可靠,终于有论文向LLJ开炮了
你的怀疑是对的!LLM作为Judge,既无效又不可靠,终于有论文向LLJ开炮了让LMM作为Judge,从对模型的性能评估到数据标注再到模型的训练和对齐流程,让AI来评判AI,这种模式几乎已经是当前学术界和工业界的常态。
来自主题: AI资讯
8867 点击 2025-08-31 12:20
 搜索
搜索
让LMM作为Judge,从对模型的性能评估到数据标注再到模型的训练和对齐流程,让AI来评判AI,这种模式几乎已经是当前学术界和工业界的常态。

在软件领域,Vibe Coding的核心在于:让开发者摆脱繁琐、低产出的代码编写,把体力活交给 AI,从而专注于更高维度的产品迭代与创意探索——追求的是效率 + 创意的双重突破。

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。

LMM在人类反馈下表现如何?新加坡国立大学华人团队提出InterFeedback框架,结果显示,最先进的LMM通过人类反馈纠正结果的比例不到50%!

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
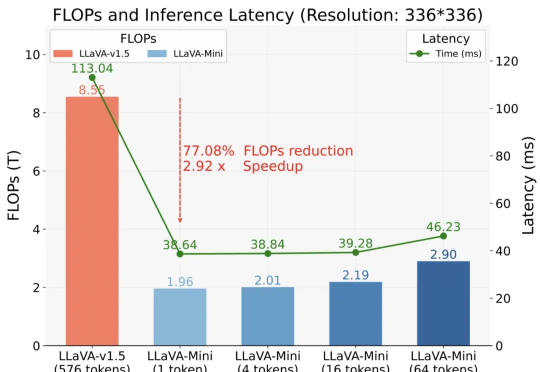
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

平面设计是一门艺术学科,它们致力于创造一些吸引注意力和有效传达信息的视觉内容。为了减轻人类设计师的负担,各种各样的海报生成模型相继被提出。它们只关注某些子任务,远未实现设计构图任务;它们在生成过程中不考虑图形设计的层次信息。为了解决这些问题,作者将分层设计原理引入多模态模型(LMM),并提出LaDeCo算法。
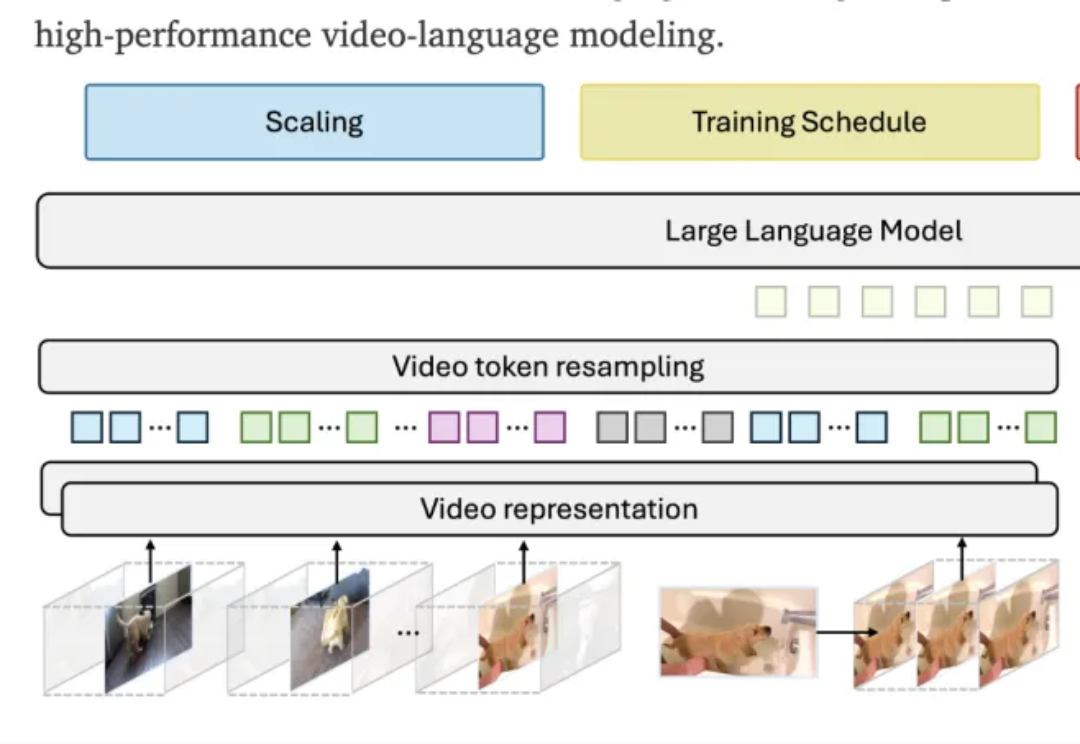
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。