
Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了
Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。
来自主题: AI技术研报
6903 点击 2026-04-22 16:39
 搜索
搜索
月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。
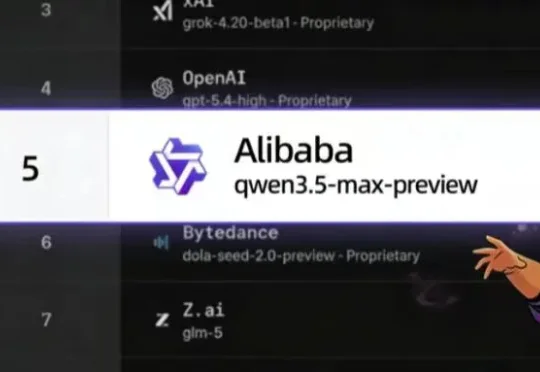
今日,阿里千问最新旗舰模型预览版Qwen3.5-Max-Preview正式亮相,并登上全球大模型评测平台LMArena。在最新榜单中,该模型拿下1464分,进入第一梯队,同时带动阿里千问跻身全球大模型实验室前五、国内第一。

用多样化的任务与公开透明的机制,堵上具身大模型刷榜的捷径。

在文心Moment大会上,文心大模型5.0正式版上线。据称,该模型参数量达2.4万亿,采用原生全模态统一建模技术,具备全模态理解与生成能力,支持文本、图像、音频、视频等多种信息的输入与输出。

谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!

一场AI界的《创造101》火了!LMArena让你盲投选出最强AI,三年从校园项目逆袭,刚刚融1.5亿美元,估值飙到17亿美元。众包投票挑战专家权威,争议四起,却已成行业标杆。你的票,就能决定下一个AI顶流!
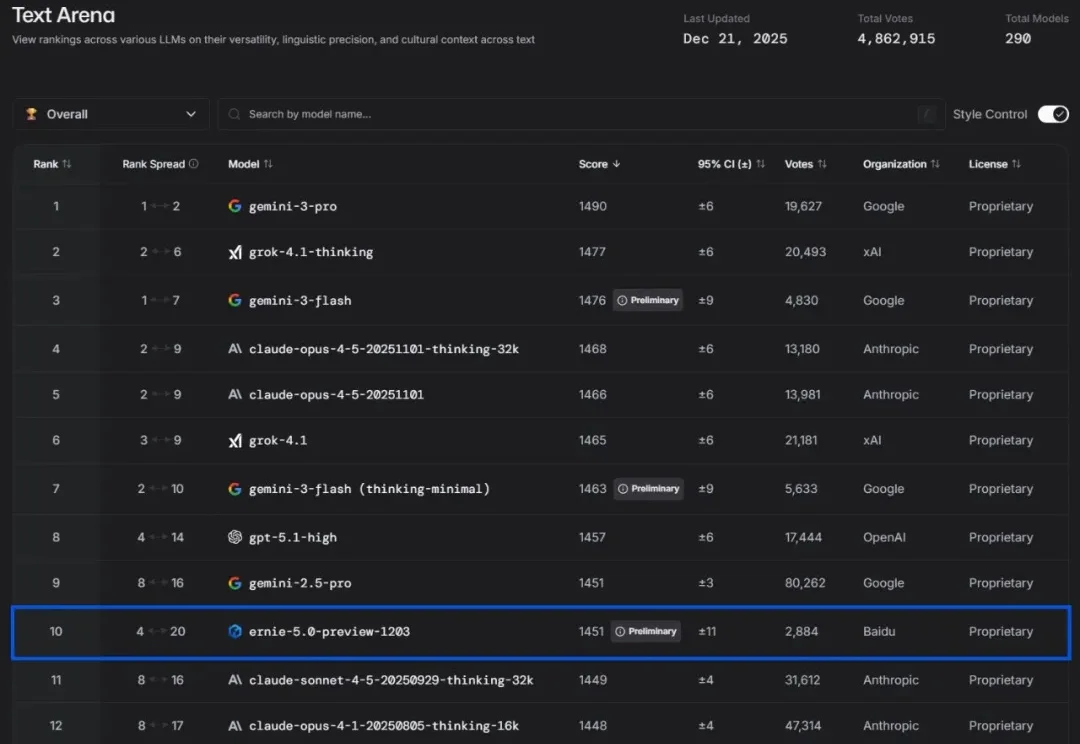
时间过得太快了,一转眼就来到了 2025 年的年底。我们距离 2026 年只剩下了 8 天。回看 AI 模型和产品突飞猛进这一年,中美两家 AI 阵营的行业发展路径有了挺大的区分,大家的关注度不再是单一模型、单一能力,而是“模型+工程+场景”的复合能力。这个变化在年底愈发明显。

AI新王来了!马斯克Grok 4.1静默上线,一夜之间登顶LMArena,Gemini 2.5 Pro却被按在地上摩擦。主打情商智商在线,算力又扩增一个数量级。这一次,Grok 4.1一共放出了两大版本:Grok 4.1 Thinking和Grok 4.1。
大模型编程最近太猛了。
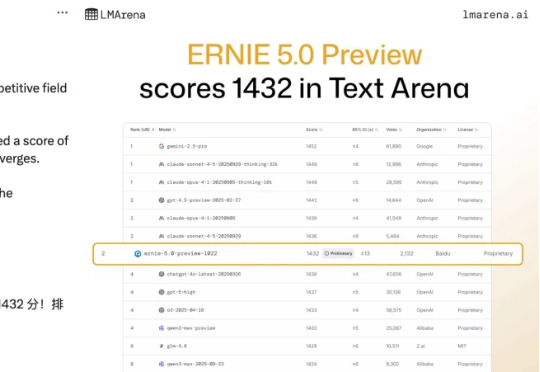
「Baidu is back」,在业界权威大模型公共基准测试平台 LMArena 发布最新一期文本竞技场排名(Text Arena)之后,有人发出了这样的惊呼。根据 11 月 8 日凌晨 LMArena 的最新排名显示,百度文心最新模型 ERNIE-5.0-Preview-1022(文心 5.0 Preview)在文本榜单上一举跃居全球并列第二、国内第一。