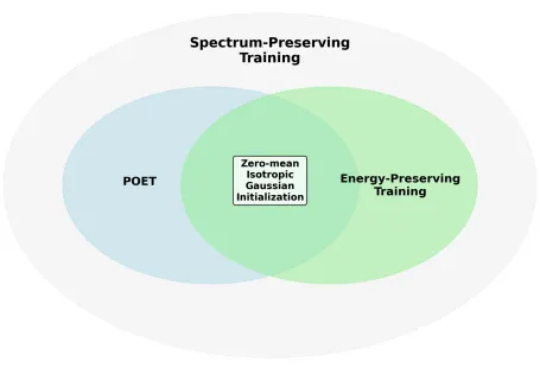
比Adam更有效,POET从谱不变原理出发,让LLM训练又稳又快
比Adam更有效,POET从谱不变原理出发,让LLM训练又稳又快Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员
来自主题: AI技术研报
10459 点击 2025-07-15 10:11
 搜索
搜索
Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员
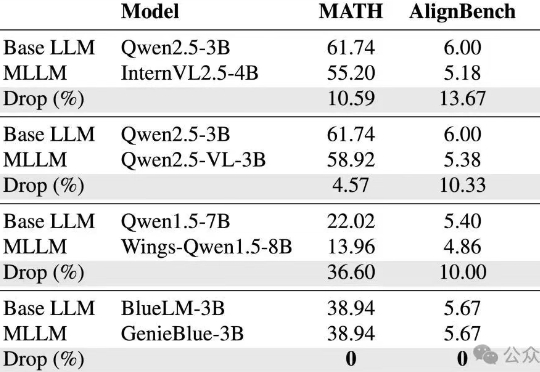
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。

LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。

ChatGPT能耗惊人,该怎么解?谷歌DeepMind新算法JEST问世,让LLM训练的迭代次数降低13倍,计算量减少10倍,或将重塑AI未来。

近日,西交微软北大联合提出信息密集型训练大法,使用纯数据驱动的方式,矫正LLM训练过程产生的偏见,在一定程度上治疗了大语言模型丢失中间信息的问题。

自从ChatGPT发布后,各种基于大模型的产品也快速融入了普通人的生活中,但即便非AI从业者在使用过几次后也可以发现,大模型经常会胡编乱造,生成错误的事实。

我们都知道,大语言模型(LLM)能够以一种无需模型微调的方式从少量示例中学习,这种方式被称为「上下文学习」(In-context Learning)。这种上下文学习现象目前只能在大模型上观察到。比如 GPT-4、Llama 等大模型在非常多的领域中都表现出了杰出的性能,但还是有很多场景受限于资源或者实时性要求较高,无法使用大模型。
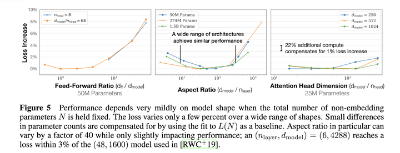
计划训练一个10B的模型,想知道至少需要多大的数据?收集到了1T的数据,想知道能训练一个多大的模型?老板准备1个月后开发布会,给的资源是100张A100,那应该用多少数据训一个多大模型最终效果最好?