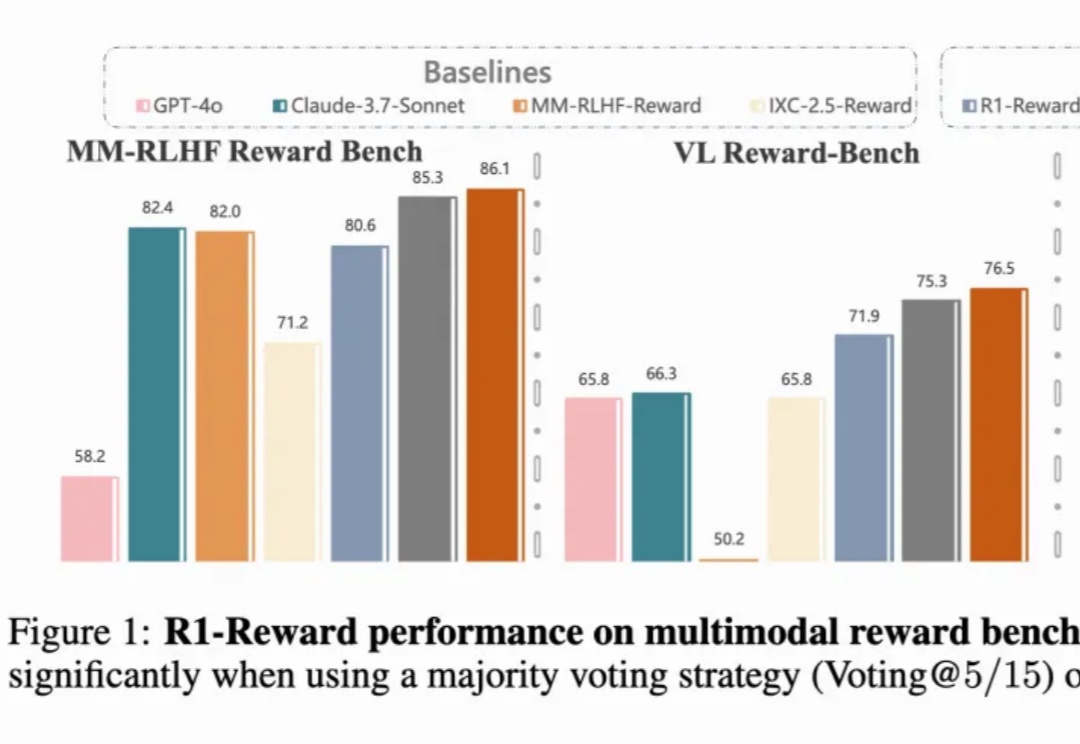
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力
突破多模态奖励瓶颈!中科院清华快手联合提出R1-Reward,用强化学习赋予模型长期推理能力多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
来自主题: AI技术研报
10145 点击 2025-05-09 11:51
 搜索
搜索
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
在前端开发领域,Vue 框架一直以其易用性和灵活性受到广大开发者的喜爱。而如今,Vue 生态在人工智能(AI)领域的应用上又迈出了重要的一步。尤雨溪近日宣布,Vue、Vite 和 Rolldown 的文档网站均已添加了llms.txt文件,这一举措旨在让大型语言模型(LLM)更方便地理解这些前端技术。

大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。
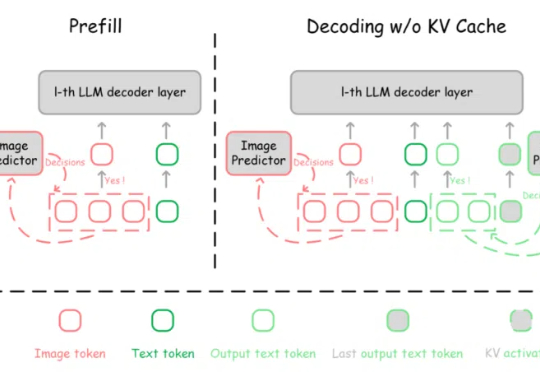
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
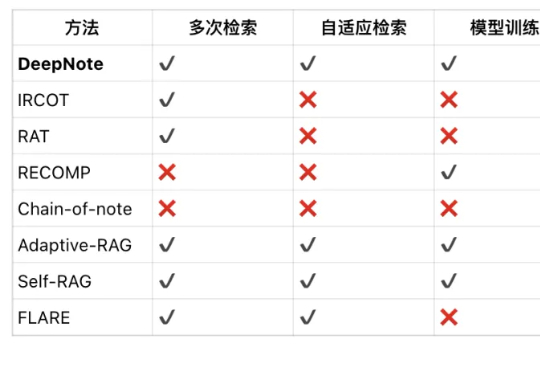
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
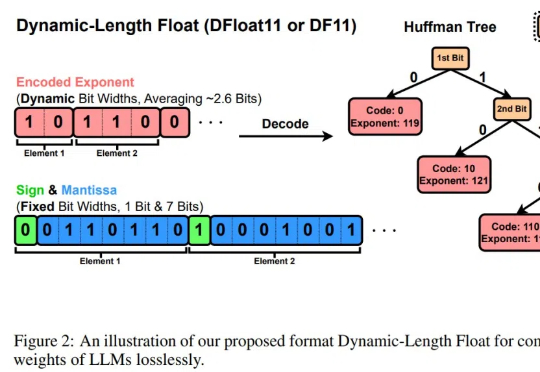
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。
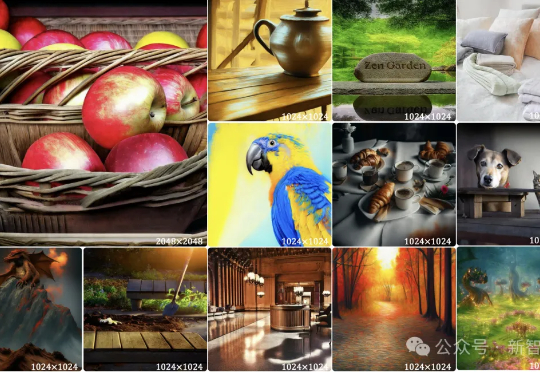
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。
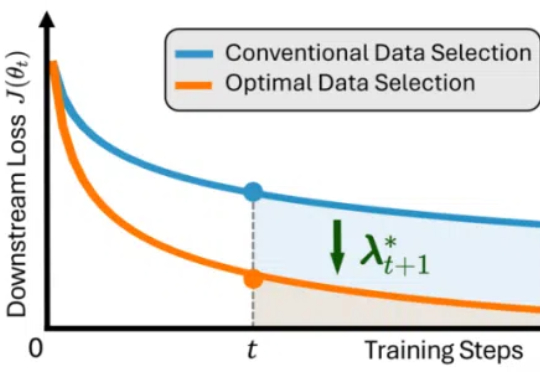
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

随着大型语言模型(LLMs)日益融入关键决策场景,其元认知能力——即识别、评估和表达自身知识边界的能力——变得尤为重要。
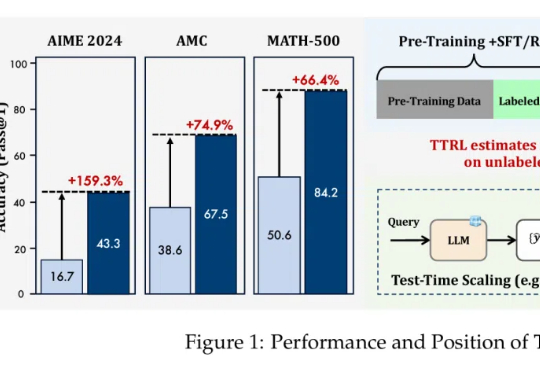
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。