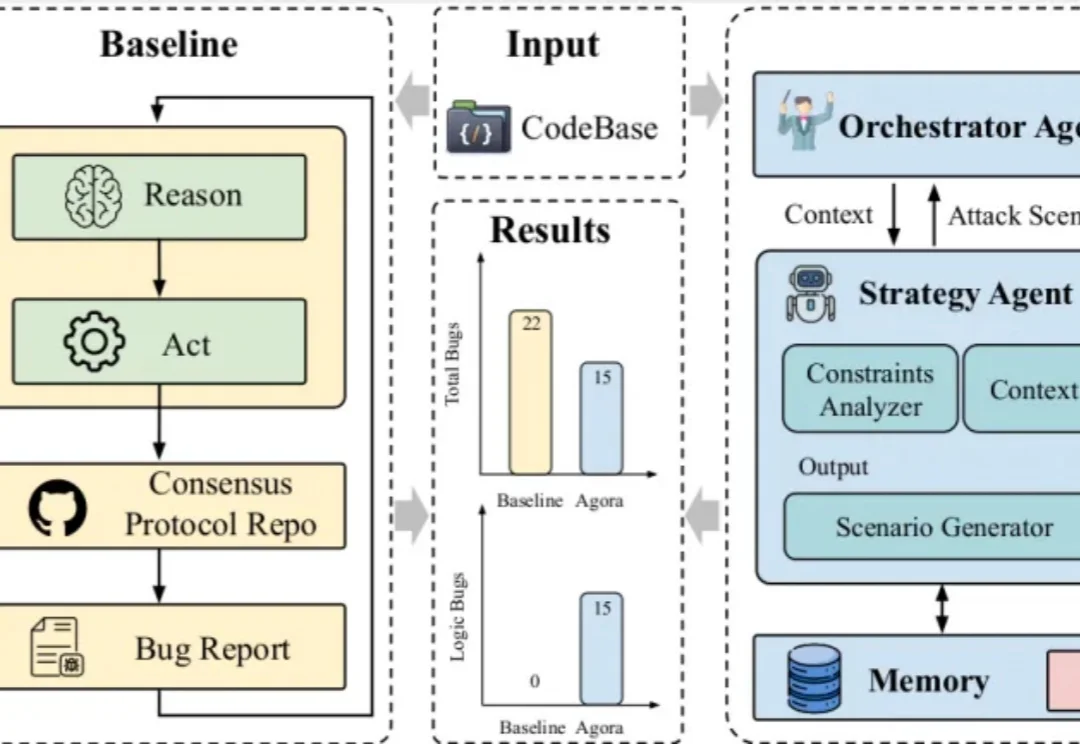
斩获15个顶级零日漏洞:0G Lab联合新国立,北大和北邮团队构建的共识协议debug智能体框架
斩获15个顶级零日漏洞:0G Lab联合新国立,北大和北邮团队构建的共识协议debug智能体框架分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。
来自主题: AI技术研报
8201 点击 2026-06-11 14:59