
摆脱OpenAI依赖!微软组建王牌AI团队专攻「小模型」,为大模型降本增效
摆脱OpenAI依赖!微软组建王牌AI团队专攻「小模型」,为大模型降本增效根据消息人士曝料,微软调集了各组中的精英,组建了一支新的AI团队,专攻小模型,希望能够摆脱对于OpenAI的依赖。
来自主题: AI技术研报
4814 点击 2024-01-24 13:03
 搜索
搜索
根据消息人士曝料,微软调集了各组中的精英,组建了一支新的AI团队,专攻小模型,希望能够摆脱对于OpenAI的依赖。
“AI 是否会取代软件工程师”是自大模型爆火以来程序员们最为关心的一大话题,事关编程的未来与我们每一位程序员。本文作者 Babel CEO、多年的资深程序员张海龙深入技术本质,为我们进行了答疑解惑。

自从ChatGPT发布后,各种基于大模型的产品也快速融入了普通人的生活中,但即便非AI从业者在使用过几次后也可以发现,大模型经常会胡编乱造,生成错误的事实。

谷歌和威斯康星麦迪逊大学的研究人员推出了一个让LLM给自己输出打分的选择性预测系统,通过软提示微调和自评估学习,取得了比10倍规模大的模型还要好的成绩,为开发下一代可靠的LLM提供了一个非常好的方向。

号称要干翻所有APP的Rabbit R1,短短5天时间已经卖了50000台!

瑞士信息与通信科技公司Lakera成立于2021年,该公司为生成式AI应用程序开发的安全工具拥有专有的威胁情报数据库,可防御对大型语言模型(LLM)的各类攻击并对AI应用程序进行压力测试检测漏洞,为AI应用程序提供企业级的安全保护。

AI训AI必将成为一大趋势。Meta和NYU团队提出让大模型「自我奖励」的方法,让Llama2一举击败GPT-4 0613、Claude 2、Gemini Pro领先模型。

IPA 已经成了现代智能手机不可或缺的标配,近期的一篇综述论文更是认为「个人 LLM 智能体会成为 AI 时代个人计算的主要软件范式」。

自 ChatGPT 等大型语言模型推出以来,为了提升模型效果,各种指令微调方法陆续被提出。本文中,普林斯顿博士生、陈丹琦学生高天宇汇总了指令微调领域的进展,包括数据、算法和评估等。
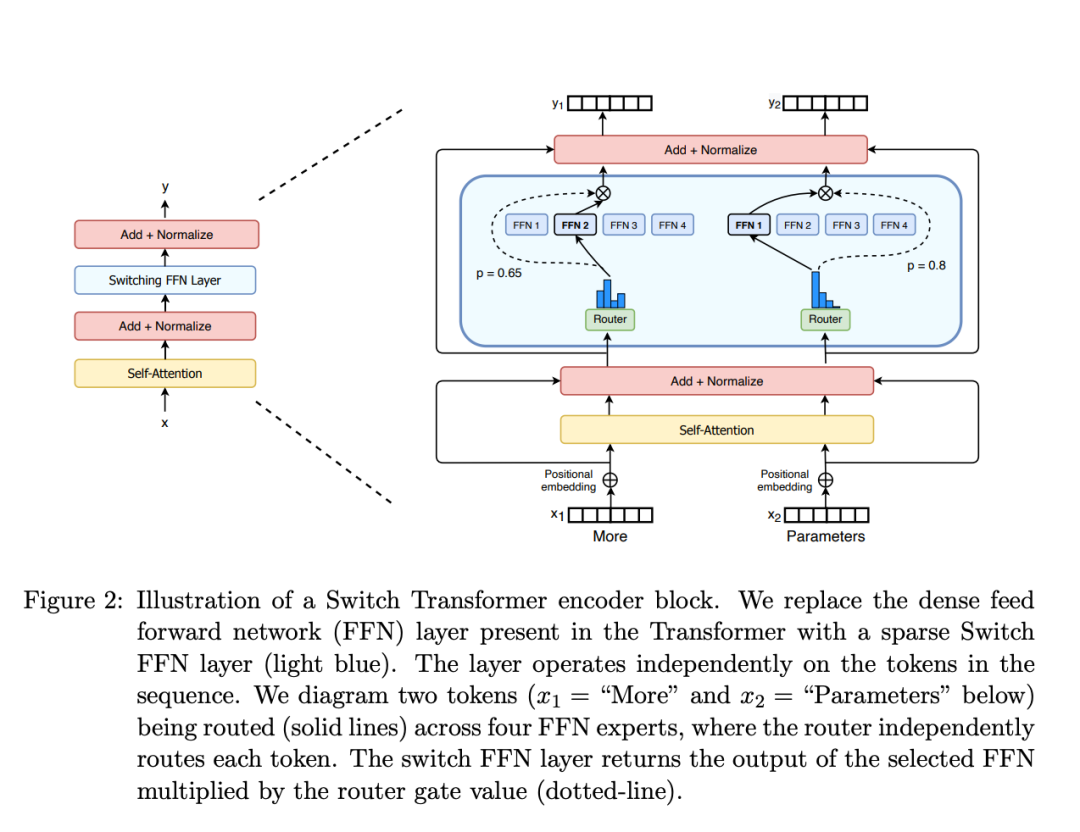
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。