
GPT-4准确率最高飙升64%!斯坦福OpenAI重磅研究:全新Meta-Prompting方法让LLM当老板
GPT-4准确率最高飙升64%!斯坦福OpenAI重磅研究:全新Meta-Prompting方法让LLM当老板大模型幻觉问题还有另一种解法?斯坦福联手OpenAI研究人员提出「元提示」新方法,能够让大模型成为全能「指挥家」,汇聚不同专家模型精华,让GPT-4的输出更精准。
来自主题: AI资讯
10083 点击 2024-01-29 16:34
 搜索
搜索
大模型幻觉问题还有另一种解法?斯坦福联手OpenAI研究人员提出「元提示」新方法,能够让大模型成为全能「指挥家」,汇聚不同专家模型精华,让GPT-4的输出更精准。
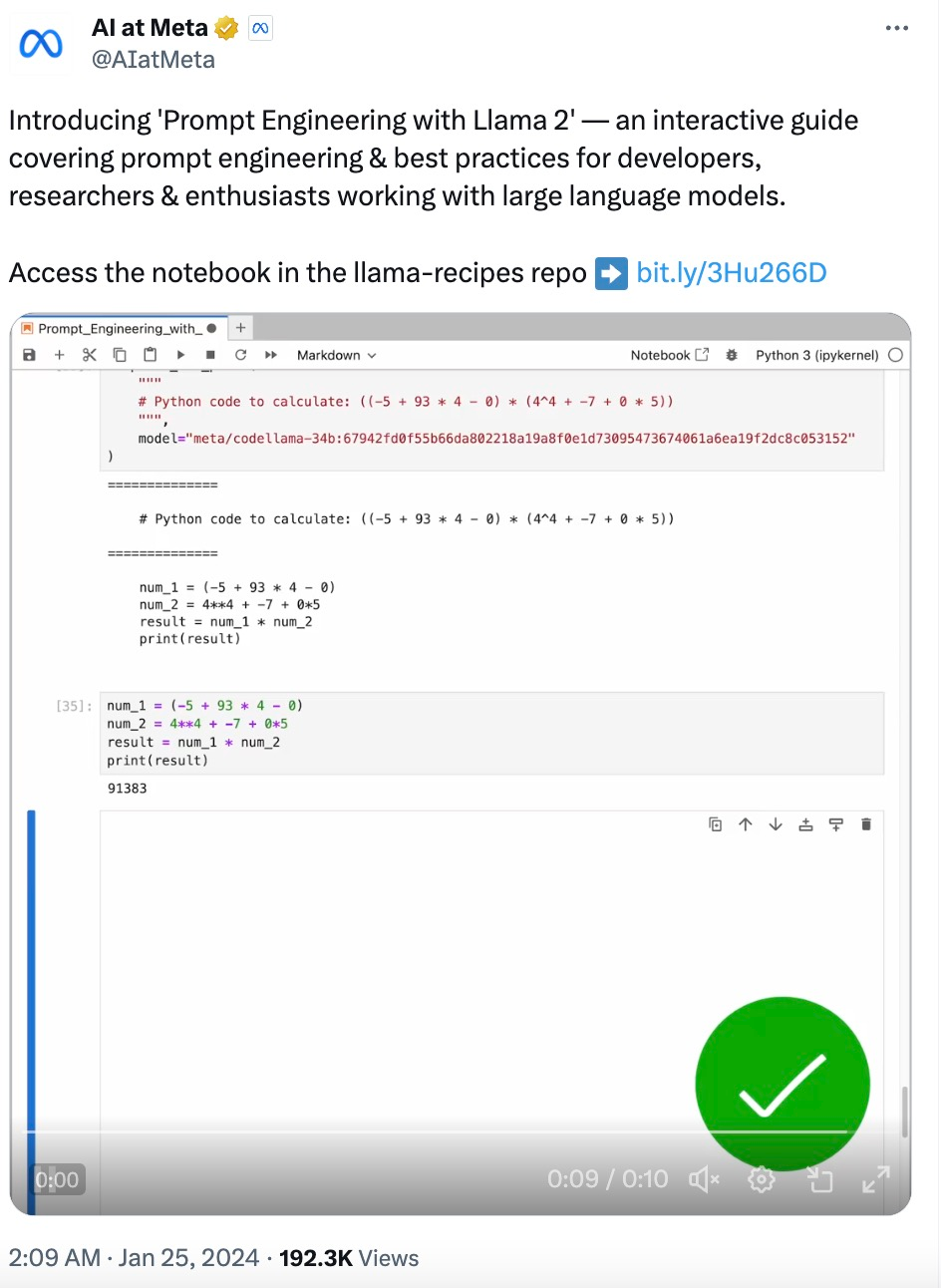
随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。

如果语言模型是巫师,代码预训练就是魔杖!

谷歌Bard又行了?在第三方LLM「排位赛」排行榜上,Bard击败GPT-4成为第二名。Jeff Dean兴奋宣布:谷歌回来了!

最新科学大模型浦科化学(ChemLLM),发布即开源!

1 月 24 日,Nature Machine Intelligence 杂志在《Anniversary AI reflections》(周年人工智能反思)专题中,再次联系并采访了近期在期刊发表评论和观点文章的作者,请他们从各自所在领域中举例说明人工智能如何改变科学过程。
![WebVoyager:借助强大多模态模型,开创全新的网络智能体 [译]](https://www.aitntnews.com/pictures/2024/1/28/f64282bb-bd95-11ee-ba64-fa163e4b35c9.png)
借助强大多模态模型,开创全新的网络智能体 Hongliang He1,3∗, Wenlin Yao2, Kaixin Ma2, Wenhao Yu2, Yong Dai2, Hongming Zhang2, Zhenzhong Lan3, Dong Yu2 1 浙江大学,2 腾讯 AI 实验室,3 西湖大学

融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM

本文介绍首个大模型时代下的文本水印综述,由清华、港中文、港科广、UIC、北邮联合发布,全面阐述了大模型时代下文本水印技术的算法类别与设计、评估角度与指标、实际应用场景,同时深入探讨了相关研究当前面临的挑战以及未来发展的方向,探索文本水印领域的前沿趋势。

Pika北大斯坦福联手,开源最新文本-图像生成/编辑框架!