
阿里、百度双双出手,大模型长文本时代终于到来?
阿里、百度双双出手,大模型长文本时代终于到来?AGI时代,越来越近了。本月,中国初创AGI(通用人工智能)公司月之暗面宣布旗下大模型工具Kimi Chat正式升级到200万字参数量,与五个月前该大模型初次亮相时的20万字相比,提升十倍。Kimi Chat的升级彻底引爆市场,同时也引起长文本大模型(Long-LLM)细分赛道更加激烈的竞争。
来自主题: AI资讯
8494 点击 2024-03-25 10:20
 搜索
搜索
AGI时代,越来越近了。本月,中国初创AGI(通用人工智能)公司月之暗面宣布旗下大模型工具Kimi Chat正式升级到200万字参数量,与五个月前该大模型初次亮相时的20万字相比,提升十倍。Kimi Chat的升级彻底引爆市场,同时也引起长文本大模型(Long-LLM)细分赛道更加激烈的竞争。
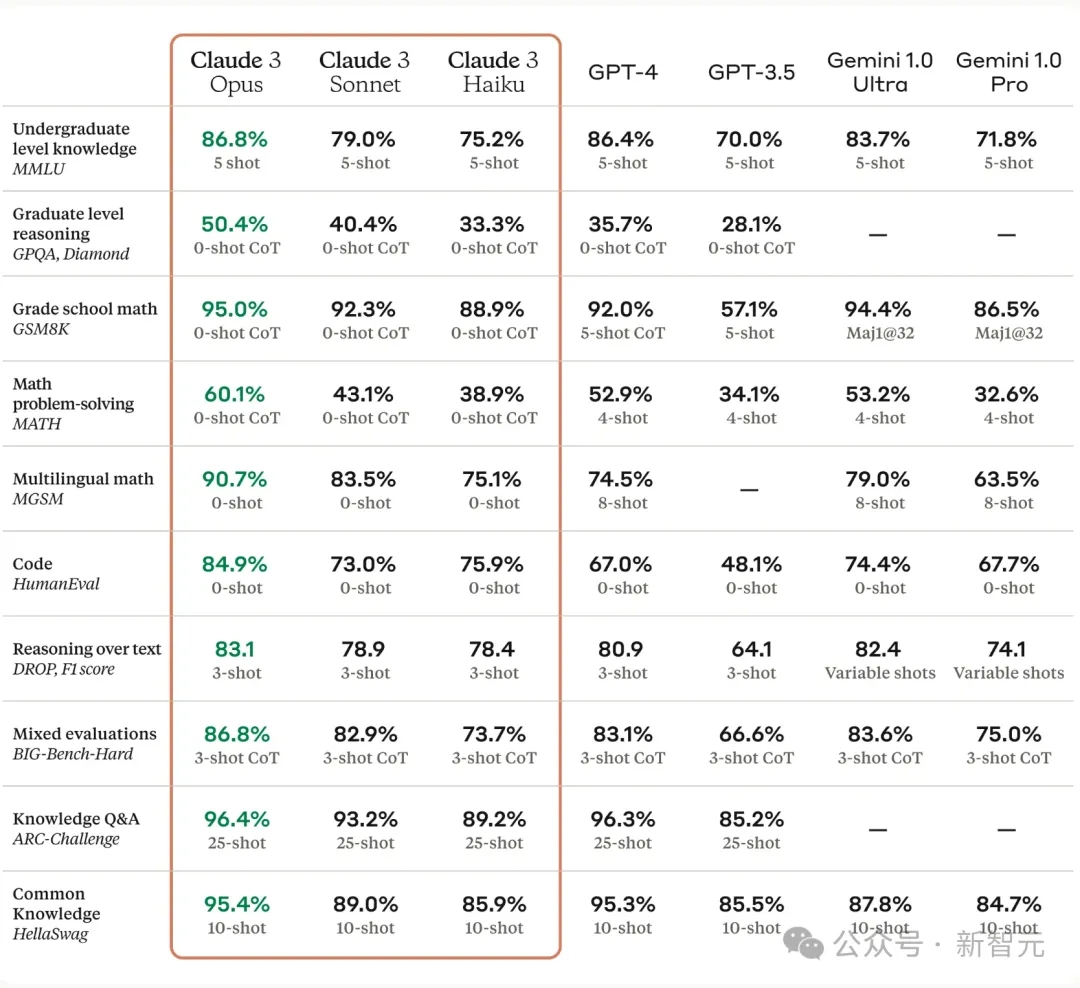
Claude 3不但数据集跑分领先,用户体验上也将成为最强大的LLM,GPT-5在哪里?

斯坦福的一篇案例研究表示,提交给AI会议的同行评审文本中,有6.5%到16.9%可能是由LLM大幅修改的,而这些趋势可能在个体级别上难以察觉。

SOTA 语音合成效果。文本到语音合成(Text to Speech,TTS)作为生成式人工智能(Generative AI 或 AIGC)的重要课题,在近年来取得了飞速发展。在大模型(LLM)时代下,语音合成技术能够扩展大模型的语音交互能力,更是受到了广泛的关注。
下一步是智能体?随着 ChatGPT、GPT-4、Sora 的陆续问世,人工智能的发展趋势引起了广泛关注,特别是 Sora 让生成式 AI 模型在多模态方面取得显著进展。人们不禁会问:人工智能领域下一个突破方向将会是什么?

近年来,LLM 已经一统所有文本任务,展现了基础模型的强大潜力。一些视觉基础模型如 CLIP 在多模态理解任务上同样展现出了强大的泛化能力,其统一的视觉语言空间带动了一系列多模态理解、生成、开放词表等任务的发展。然而针对更细粒度的目标级别的感知任务,目前依然缺乏一个强大的基础模型。
AGI竞赛,正在大科技公司之间紧锣密鼓地展开,作为万亿显卡帝国掌舵人的老黄自然也不会缺席。在最近举办的GTC 2024上,老黄发表了自己对于AGI以及幻觉问题的看法。
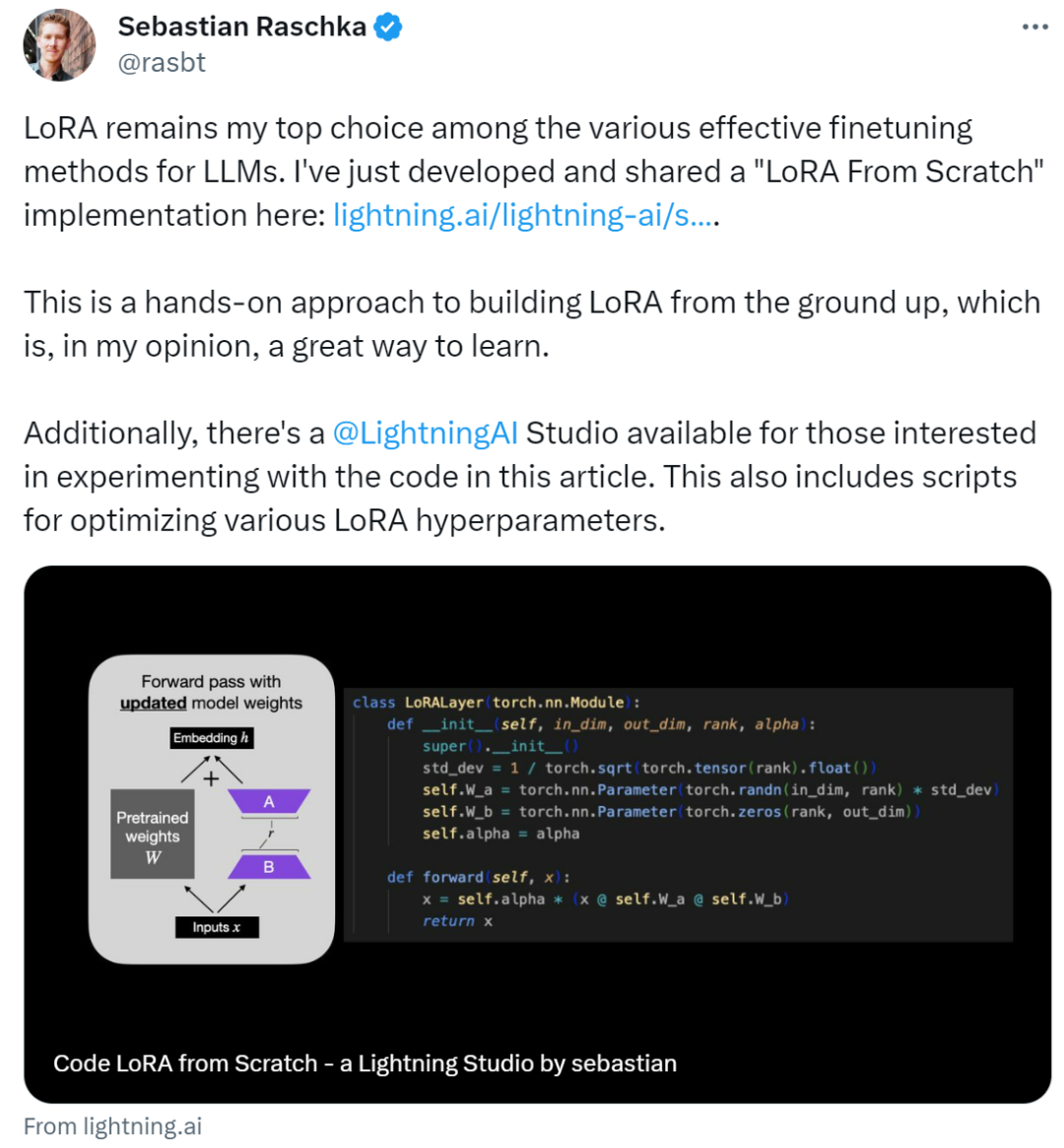
作者表示:在各种有效的 LLM 微调方法中,LoRA 仍然是他的首选。LoRA(Low-Rank Adaptation)作为一种用于微调 LLM(大语言模型)的流行技术,最初由来自微软的研究人员在论文《 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 》中提出。

近日,来自MIT的研究人员发表了关于大模型能力增速的研究,结果表明,LLM的能力大约每8个月就会翻一倍,速度远超摩尔定律!硬件马上就要跟不上啦!

早在 2020 年,陶大程团队就发布了《Knowledge Distillation: A Survey》,详细介绍了知识蒸馏在深度学习中的应用,主要用于模型压缩和加速。随着大语言模型的出现,知识蒸馏的作用范围不断扩大,逐渐扩展到了用于提升小模型的性能以及模型的自我提升。