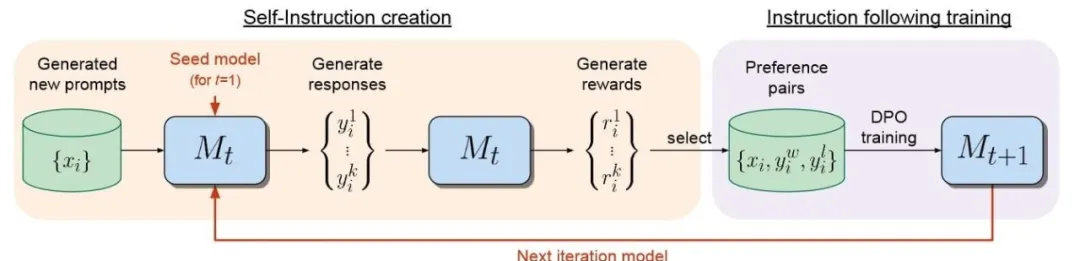
「用 AI 训 AI」这事靠谱吗?
「用 AI 训 AI」这事靠谱吗?在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。
来自主题: AI技术研报
10451 点击 2024-05-01 19:31
 搜索
搜索
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token
前不久,斯坦福大学教授吴恩达在演讲中提到了智能体的巨大潜力,这也引起了众多讨论。其中,吴恩达谈到基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。这表明,将目光局限于大模型不一定可取,智能体或许会比其所用的基础模型更加优秀。
前不久,斯坦福大学教授吴恩达在演讲中提到了智能体的巨大潜力,这也引起了众多讨论。其中,吴恩达谈到基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。这表明,将目光局限于大模型不一定可取,智能体或许会比其所用的基础模型更加优秀。

近期,多模态大模型 (MLLM) 在文本中心的 VQA 领域取得了显著进展,尤其是多个闭源模型,例如:GPT4V 和 Gemini,甚至在某些方面展现了超越人类能力的表现。
Snowflake 发布高「企业智能」模型 Arctic,专注于企业内部应用。

在人工智能的前沿领域,大语言模型(Large Language Models,LLMs)由于其强大的能力正吸引着全球研究者的目光。在 LLMs 的研发流程中,预训练阶段占据着举足轻重的地位,它不仅消耗了大量的计算资源,还蕴含着许多尚未揭示的秘密。
AI,能够重写人类基因组了? 就在刚刚,初创公司Profluent宣布,完全由AI设计的基因编辑器,已经成功编辑了人类细胞中的DNA。

在对齐大型语言模型(LLM)与人类意图方面,最常用的方法必然是根据人类反馈的强化学习(RLHF)

虽然大型语言模型(LLM)在各种常见的自然语言处理任务中展现出了优异的性能,但随之而来的幻觉,也揭示了模型在真实性和透明度上仍然存在问题。